如何最有效地处理大量文件描述符?
对于处理大量套接字连接的程序(例如Web服务,p2p系统等),似乎有几种选择。
- 生成一个单独的线程来处理每个套接字的I / O.
- 使用select系统调用将I / O多路复用到一个线程中。
- 使用poll系统调用来多路复用I / O(替换选择)。
- 使用epoll系统调用,以避免必须通过用户/系统边界重复发送套接字fd。
- 产生许多I / O线程,每个线程使用poll API复用一组相对较小的连接总数。
- 按照#5,除了使用epoll API为每个独立的I / O线程创建单独的epoll对象。
在多核CPU上,我希望#5或#6具有最佳性能,但我没有任何硬数据支持这一点。搜索网页出现了this页面,描述了上述作者测试方法#2,#3和#4的经验。不幸的是,这个网页大约有7年的历史,没有明显的最新更新。
所以我的问题是,哪些方法让人们发现效率最高和/或是否有另一种方法比上面列出的方法更好?将赞赏对现实生活图表,白皮书和/或网络可用文章的参考。
4 个答案:
答案 0 :(得分:3)
根据我运行大型IRC服务器的经验,我们曾经使用select()和poll()(因为epoll()/ kqueue()不可用)。在大约700个并发客户端,服务器将使用100%的CPU(irc服务器不是多线程的)。然而,有趣的是服务器仍然表现良好。在大约4,000个客户端,服务器将开始滞后。
原因是大约有700个客户,当我们回到select()时,会有一个客户端可供处理。 for()循环扫描以找出它将占用大部分CPU的客户端。随着我们获得更多客户,我们开始越来越多的客户需要在每次调用select()时进行处理,因此我们会变得更有效率。
转向epoll()/ kqueue(),类似规格的机器可以轻松处理10,000个客户端,其中一些(可靠的更强大的机器,但仍然被当今标准认为很小的机器),拥有30,000个客户端没有出汗。
我在SIGIO上看到的实验似乎表明它适用于延迟非常重要的应用程序,其中只有少数活跃客户端从事很少的个人工作。
我建议在几乎任何情况下都使用epoll()/ kqueue()而不是select()/ poll()。我没有尝试在线程之间拆分客户端。说实话,我从来没有找到过一项服务,需要在前端客户端处理上完成更多的操作,以证明线程的实验是合理的。
答案 1 :(得分:2)
根据我的经验,你将获得#6的最佳表现。
我还建议你研究一下libevent来处理抽象的一些细节。至少,您将能够看到他们的一些基准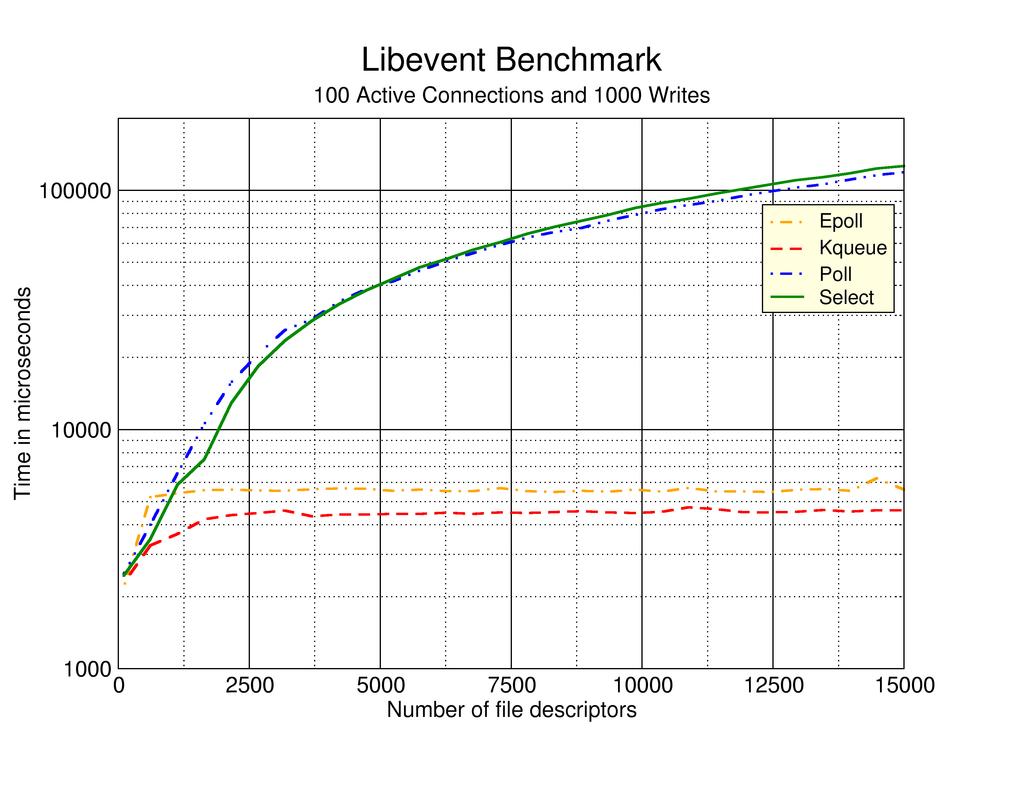 。
。
另外,你讲的是多少个插座?在你开始获得至少几百个插槽之前,你的方法可能并不重要。
答案 2 :(得分:2)
我花了两年时间研究这个特定的问题(对于G-WAN网络服务器,它带有许多基准测试和图表暴露所有这些)。
在Linux下运行最佳的模型是带有一个事件队列的epoll(对于繁重的处理,有几个工作线程)。
如果你的处理很少(处理延迟很低),那么使用多个线程使用一个线程会更快。
原因是epoll无法在多核CPU上扩展(在同一用户模式应用程序中使用多个并发epoll队列进行连接I / O只会降低服务器速度)。
我没有认真考虑内核中的epoll代码(到目前为止我只专注于用户模式),但我的猜测是内核中的epoll实现被锁定了。
这就是为什么使用多个线程快速碰壁。
毫无疑问,如果Linux希望保持其作为性能最佳内核之一的地位,那么这种糟糕的状态不应该持续下去。
答案 3 :(得分:0)
我广泛使用epoll(),效果很好。我经常有数千个套接字处于活动状态,最多可以测试131,072个套接字。 epoll()总能处理它。
我使用多个线程,每个线程轮询一个套接字子集。这使代码变得复杂,但充分利用了多核CPU。
- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?