使用正则表达式提取PHP代码
我想用正则表达式提取本节的整个PHP代码:
<h1>Extract the PHP Code</h1>
<?php
echo(date("F j, Y, g:i a") . ' and a stumbling block: ?>');
/* Another stumbling block ?> */
echo(' that works.');
?>
<p>Some HTML text ...</p>
不幸的是,我的正则表达式陷入了绊脚石:
/<[?]php[^?>]*[?]>/gim
是否有人提示如何捕获完整的PHP代码?
2 个答案:
答案 0 :(得分:4)
这样的事情可能会起作用
/<\?php.+?\?>$/ms
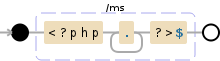
此模式使用两个flags
-
mPCRE_MULTILINE默认情况下,PCRE将主题字符串视为由单个“行”字符组成(即使它实际上包含多个换行符)。 “行首”元字符(
^)仅在字符串的开头匹配,而“行尾”元字符($)仅在字符串的末尾匹配,或者在字符串的末尾匹配。终止换行符(除非设置了 D 修饰符)。这与Perl相同。设置此修饰符时,“行首”和“行尾”构造分别在主题字符串中的任何换行符之后或之前立即匹配,以及在开头和结尾处匹配。这相当于Perl的/m修饰符。如果主题字符串中没有"\n"个字符,或者模式中没有出现^或$,则设置此修饰符无效。 -
sPCRE_DOTALL如果设置了此修饰符,则模式中的点元字符将匹配所有字符,包括换行符。没有它,排除了换行符。此修饰符等效于Perl的
/s修饰符。像[^a]这样的否定类总是匹配换行符,与此修饰符的设置无关。
以下是几场比赛的样子

警告如果在一行末尾找不到?>,则无效。
所以它适用于
-
?>'); -
?> */
但它不适用于
<?php
echo "actual code";
/*
* comment ?>
*/
?>
简而言之,如果你的代码很混乱,你需要一个更好的解决方案。如果您的代码是干净的,它应该可以正常工作。
答案 1 :(得分:3)
您可以尝试使用此模式:
$pattern = <<<'LOD'
~
#definitions
(?(DEFINE)
(?<sq> '(?>[^'\\]+|\\.)*+(?>'|\z) ) # content inside simple quotes
(?<dq> "(?>[^"\\]+|\\.)*+(?>"|\z) ) # content inside double quotes
(?<vn> [a-zA-Z_]\w*+ ) # variable name
(?<crlf> \r?\n ) # CRLF
(?<hndoc> <<< (["']?) (\g<vn>) \g{-2} \g<crlf> # content inside here/nowdoc
(?> [^\r\n]+ | \R+ (?!\g{-1}; $) )*+
(?: \g<crlf> \g{-1}; \g<crlf> | \z )
)
(?<cmt> /\* # multiline comments
(?> [^*]+ | \* (?!/) )*+
\*/
)
)
#pattern
<\?php \s+
(?> [^"'?/<]+ | \?+(?!>) | \g<sq> | \g<dq> | \g<hndoc> | \g<cmt> | [</]+ )*+
(?: \?> | \z )
~xsm
LOD;
测试:
$subject = <<<'LOD'
<h1>Extract the PHP Code</h1>
<?php
echo(date("F j, Y, g:i a") . ' and a stumbling block: ?>');
/* Another stumbling block ?> */
echo <<<'EOD'
Youpi!!! ?>
EOD;
echo(' that works.');
?>
<p>Some HTML text ...</p>
LOD;
preg_match_all($pattern, $subject, $matches);
print_r($matches);
另一种方式:
正如马里奥在评论中建议的那样,你可以使用标记器。这是最简单的方法,因为您不必定义任何内容,例如:
$tokens = token_get_all($subject);
$display = false;
foreach ($tokens as $token) {
if (is_array($token)) {
if ($token[0]==T_OPEN_TAG) $display = true;
if ($display) echo $token[1];
if ($token[0]==T_CLOSE_TAG) $display = false;
} else {
if ($display) echo $token;
}
}
相关问题
最新问题
- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?