跨换行符和多个换行符匹配
我有两个字符值的列表,每个字符值都在Notepad ++中。我试图消除重复,但我写的只是匹配一行的字符。
所以,如果我的列表如下:
ME, <- not matched
OR, |
ME, <- not matched
RI,
IL,
SD,
NV,
VA,
VA,
NY,
MN,
IL,
CA,
MI,
MO, <- match
MO, <- match
现在我正在使用它。如何修改它,以便找到重复的结果多于一行
((\w{2}).*(\r\n)(\2))+
修改
((\w{2}).*(\r\n))(.*\r\n)+\1这似乎更适合位。
3 个答案:
答案 0 :(得分:0)
如果勾选“dot matches newline”复选框,您将获得三场比赛:
ME, <- matched
OR, |
ME, <- matched
RI,
IL, <- matched
SD, |
NV, |
VA, |
VA, |
NY, |
MN, |
IL, <- matched
CA,
MI,
MO, <- matched
MO, <- matched
但这不会帮助您删除重复项..
答案 1 :(得分:0)
(\w{2}),[^\1]*(\1),
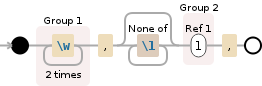
我相信这是你能得到的最接近的。
编辑:我喜欢,大声笑这会起作用。我不确定你使用的是哪种语言,但很难给你伪造的代码。
基本上,
pattern = "(\w{2}),[^]*(\1),";
compile(pattern);
while(match(pattern, input)){
//replace input's group 2 with a "" and remove /r/n
}
这将继续运行代码,直到您没有重复项。
答案 2 :(得分:0)
也许这不是首选的答案,但我会写一个小的python脚本来完成这个任务......
my_file = """ME,
OR,
ME,
RI,
IL,
SD,
NV,
VA,
VA,
NY,
MN,
IL,""" #replace by my_file = file("filename.txt", "r")
my_set = set()
for line in my_file.splitlines():
my_set.add(line)
print my_set #just for demonstartion
out_file = file("C:\\Users\\burgert\\Desktop\\outfile.txt", "w")
for s in my_set:
s += "\n"
out_file.writelines(s)
out_file.close()
相关问题
最新问题
- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?