正则表达式忽略锚点包围的标签
是否可以以及如何仅选择未被锚<a></a>标记包围的标记?
我不可能改变整个系统来使用类似DOMDocument的东西,所以我坚持使用正则表达式。
已经搜索了一段时间,但似乎(或不知道如何)找到我需要的答案。
我目前正在使用简单的正则表达式来选择我想要选择的所有标签,但我必须排除一些被锚点包围的标签,我不知道如何解决这个问题。任何帮助表示赞赏。
示例数据
Suspendisse potenti. Nam pellentesque eu lectus eget convallis.
Curabitur <span>porta metus sem</span>, nec fermentum urna elementum ac.
Praesent et ultrices urna. <span>Curabitur id nisl</span> in sapien ultrices laoreet vel et quam.
Cras nisi felis, vestibulum id adipiscing venenatis, dignissim vel tortor.
<a><span>Integer sapien dolor</span></a>, pellentesque sed ultricies in, ornare eu felis.
Cras volutpat hendrerit odio id aliquet.
在此我选择所有<span>标签,例如'/<span>(.*?)<\/span>/',但会选择所有跨度,因为我需要的{span}标签不在{{1}之间}。
只要它完成工作,就可以进行多步骤过程,这意味着不需要使用一个表达式选择所有内容。
3 个答案:
答案 0 :(得分:0)
使用否定的lookbehind:
(?<!<a>)<span>(.*?)<\/span>
这将排除<span> - 标记位于<a> - 标记的标记。
为了完整性,如果你只需要在一个完整的环境中匹配,那么添加一个负向前瞻:
(?<!<a>)<span>(.*?)<\/span>(?!</a>)
请参阅演示:http://regexr.com?374pp
答案 1 :(得分:0)
(?<!<a.*?>)(<(?!a\b)(.*?\b).*?>.*</\2>|<(?!a\b).*?\b />)(?!</a>)
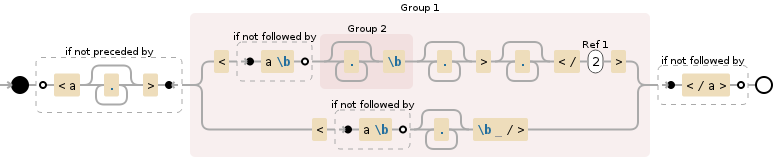
这应匹配未被--Tags
包围的每个HTML标记如果您只需要span-Tags的匹配器,请使用以下选项:
(?<!<a.*?>)<span.*?>.*</span>(?!</a>)

如果您需要有关正则表达式外观断言的更多信息:http://www.regular-expressions.info/lookaround.html
答案 2 :(得分:0)
你走了:
preg_match_all(
'%\G(?:[^<]+|<a\b[^>]*>.*?</a>|<(?!span\b)[^>]*>)*\K<span[^>]*>.*?</span>%s',
$subject, $result);
你确定你不能使用HTML解析器吗? :d
为了解释它,我首先将它放在一个更易阅读的格式中。
\G # (1)
(?:
[^<]+ # (2)
|
<a\b[^>]*>.*?</a> # (3)
|
<(?!span\b)[^>]*> # (4)
)*
\K # (5)
<span[^>]*>.*?</span>
以下是它的工作原理:
-
\G强制每场连续比赛从上一场比赛结束的位置开始。 -
任何不是标签开头的内容
-
一个完整的
<a>元素(假设它们从不包含其他<a>元素) -
除
<span>之外的任何其他标记
-
\K重置匹配开始位置,因此到目前为止匹配的所有内容都不会被视为匹配的一部分。它实际上是一个积极的外观,不关心它匹配多少个字符。
通常的免责声明适用。即使在完全有效的HTML中,这种正则表达式也有很多失败的方法。例如,它假定左尖括号(<)始终标记标记的开头,当它可以在许多其他地方找到时。
- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?