使用preg_replace进行可变长度屏蔽
我使用preg_replace_callback()屏蔽字符串中单引号(包含)之间的所有字符。但我想尽可能只使用preg_replace(),但一直无法弄清楚。任何帮助将不胜感激。
这就是我使用preg_replace_callback()生成正确输出的内容:
function maskCallback( $matches ) {
return str_repeat( '-', strlen( $matches[0] ) );
}
function maskString( $str ) {
return preg_replace_callback( "('.*?')", 'maskCallback', $str );
}
$str = "TEST 'replace''me' ok 'me too'";
echo $str,"\n";
echo $maskString( $str ),"\n";
输出是:
TEST 'replace''me' ok 'me too'
TEST ------------- ok --------
我尝试过使用:
preg_replace( "/('.*?')/", '-', $str );
但破折号被消耗掉了,例如:
TEST -- ok -
我尝试的其他任何东西都不起作用。 (我显然不是正则表达式专家。)这可能吗?如果是这样,怎么样?
3 个答案:
答案 0 :(得分:16)
是的,你可以这样做,(假设引号是平衡的)例子:
$str = "TEST 'replace''me' ok 'me too'";
$pattern = "~[^'](?=[^']*(?:'[^']*'[^']*)*+'[^']*\z)|'~";
$result = preg_replace($pattern, '-', $str);
这个想法是:你可以替换一个字符,如果它是一个引号,或者它后跟一个奇数引号。
没有引号:
$pattern = "~(?:(?!\A)\G|(?:(?!\G)|\A)'\K)[^']~";
$result = preg_replace($pattern, '-', $str);
只有当一个字符与先前匹配相邻时(换句话说,当它紧接在最后一个匹配之后)或者它前面跟一个与先前匹配不相邻的引用时,该模式才匹配一个字符。 / p>
\G是最后一场比赛后的位置(开头是字符串的开头)
模式细节:
~ # pattern delimiter
(?: # non capturing group: describe the two possibilities
# before the target character
(?!\A)\G # at the position in the string after the last match
# the negative lookbehind ensure that this is not the start
# of the string
| # OR
(?: # (to ensure that the quote is a not a closing quote)
(?!\G) # not contiguous to a precedent match
| # OR
\A # at the start of the string
)
' # the opening quote
\K # remove all precedent characters from the match result
# (only one quote here)
)
[^'] # a character that is not a quote
~
请注意,由于结束引号与模式不匹配,因此不能匹配以下不是引号的字符,因为没有先例匹配。
编辑:
(*SKIP)(*FAIL)方式:
您可以使用回溯控制动词(?:(?!\G)|\A)'和{{1>来测试单引号是否与先前模式中的(*SKIP)结束引号不同,而不是测试结束引号的匹配连续性。 (可以缩短为(*FAIL))。
(*F)由于每个结束引号上的模式都失败,因此在下一个开头报价之前不会匹配以下字符。
这种模式的写作效率可能更高:
$pattern = "~(?:(?!\A)\G|')(?:'(*SKIP)(*F)|\K[^'])~";
$result = preg_replace($pattern, '-', $str);
(您也可以使用$pattern = "~(?:\G(?!\A)(?:'(*SKIP)(*F))?|'\K)[^']~";
代替(*PRUNE)。)
答案 1 :(得分:12)
简短回答:这有可能!!!
使用以下模式
' # Match a single quote
(?= # Positive lookahead, this basically makes sure there is an odd number of single quotes ahead in this line
(?:(?:[^'\r\n]*'){2})* # Match anything except single quote or newlines zero or more times followed by a single quote, repeat this twice and repeat this whole process zero or more times (basically a pair of single quotes)
(?:[^'\r\n]*'[^'\r\n]*(?:\r?\n|$)) # You guessed, this is to match a single quote until the end of line
)
| # or
\G(?<!^) # Preceding contiguous match (not beginning of line)
[^'] # Match anything that's not a single quote
(?= # Same as above
(?:(?:[^'\r\n]*'){2})* # Same as above
(?:[^'\r\n]*'[^'\r\n]*(?:\r?\n|$)) # Same as above
)
|
\G(?<!^) # Preceding contiguous match (not beginning of line)
' # Match a single quote
确保使用m修饰符。
答案很长:这很痛苦:)
除非你,但你的整个团队都喜欢正则表达式,你可能会想到使用这个正则表达式,但要记住这对于初学者来说是疯狂的并且很难掌握。可读性(几乎)总是先行。
我会打破我如何编写这样一个正则表达式的想法:
1)我们首先需要知道我们实际想要替换的内容,我们希望用连字符替换两个单引号之间的每个字符(包括单引号)。
2)如果我们要使用preg_replace(),则表示我们的模式每次都需要匹配一个字符。
3)所以第一步显而易见:'
4)我们将使用\G,这意味着匹配字符串的开头或我们之前匹配的连续字符。举一个简单的例子~a|\Gb~。如果它位于开头,则匹配a或b;如果上一个匹配为b,则匹配a。见demo
5)我们不希望与字符串的开头有任何关系因此我们将使用\G(?<!^)。
6)现在我们需要匹配任何不是单引号~'|\G(?<!^)[^']~的内容
7)现在开始真正的痛苦,我们怎么知道上面的模式不会与c中的'ab'c匹配?那么它会,我们需要计算单引号......
让我们回顾一下:
a 'bcd' efg 'hij'
^ It will match this first
^^^ Then it will match these individually with \G(?<!^)[^']
^ It will match since we're matching single quotes without checking anything
^^^^^ And it will continue to match ...
我们想要的可以在这3条规则中完成:
a 'bcd' efg 'hij'
1 ^ Match a single quote only if there is an odd number of single quotes ahead
2 ^^^ Match individually those characters only if there is an odd number of single quotes ahead
3 ^ Match a single quote only if there was a match before this character
8)如果我们知道如何匹配偶数,请检查是否有奇数的单引号:
(?: # non-capturing group
(?: # non-capturing group
[^'\r\n]* # Match anything that's not a single quote or newline, zero or more times
' # Match a single quote
){2} # Repeat 2 times (We'll be matching 2 single quotes)
)* # Repeat all this zero or more times. So we match 0, 2, 4, 6 ... single quotes
9)奇数现在很容易,我们只需添加:
(?:
[^'\r\n]* # Match anything that's not a single quote or newline, zero or more times
' # Match a single quote
[^'\r\n]* # Match anything that's not a single quote or newline, zero or more times
(?:\r?\n|$) # End of line
)
10)在单个前瞻中合并上述内容:
(?=
(?: # non-capturing group
(?: # non-capturing group
[^'\r\n]* # Match anything that's not a single quote or newline, zero or more times
' # Match a single quote
){2} # Repeat 2 times (We'll be matching 2 single quotes)
)* # Repeat all this zero or more times. So we match 0, 2, 4, 6 ... single quotes
(?:
[^'\r\n]* # Match anything that's not a single quote or newline, zero or more times
' # Match a single quote
[^'\r\n]* # Match anything that's not a single quote or newline, zero or more times
(?:\r?\n|$) # End of line
)
)
11)现在我们需要合并之前定义的所有3条规则:
~ # A modifier
#################################### Rule 1 ####################################
' # A single quote
(?= # Lookahead to make sure there is an odd number of single quotes ahead
(?: # non-capturing group
(?: # non-capturing group
[^'\r\n]* # Match anything that's not a single quote or newline, zero or more times
' # Match a single quote
){2} # Repeat 2 times (We'll be matching 2 single quotes)
)* # Repeat all this zero or more times. So we match 0, 2, 4, 6 ... single quotes
(?:
[^'\r\n]* # Match anything that's not a single quote or newline, zero or more times
' # Match a single quote
[^'\r\n]* # Match anything that's not a single quote or newline, zero or more times
(?:\r?\n|$) # End of line
)
)
| # Or
#################################### Rule 2 ####################################
\G(?<!^) # Preceding contiguous match (not beginning of line)
[^'] # Match anything that's not a single quote
(?= # Lookahead to make sure there is an odd number of single quotes ahead
(?: # non-capturing group
(?: # non-capturing group
[^'\r\n]* # Match anything that's not a single quote or newline, zero or more times
' # Match a single quote
){2} # Repeat 2 times (We'll be matching 2 single quotes)
)* # Repeat all this zero or more times. So we match 0, 2, 4, 6 ... single quotes
(?:
[^'\r\n]* # Match anything that's not a single quote or newline, zero or more times
' # Match a single quote
[^'\r\n]* # Match anything that's not a single quote or newline, zero or more times
(?:\r?\n|$) # End of line
)
)
| # Or
#################################### Rule 3 ####################################
\G(?<!^) # Preceding contiguous match (not beginning of line)
' # Match a single quote
~x
答案 2 :(得分:6)
嗯,只是为了它的乐趣,我认真不会推荐这样的东西,因为我试图避免在没有必要的情况下使用外观,这是一个使用&#39概念的正则表达式; 回到未来&#39;:
(?<=^|\s)'(?!\s)|(?!^)(?<!'(?=\s))\G.
好的,它分为两部分:
<强> 1。匹配开头的单引号
(?<=^|\s)'(?!\s)
我认为应该在此建立的规则是:
- 在开头引号之前应该有
^或\s(因此(?<=^|\s))。 - 开头引号后面没有
\s(因此(?!\s))。 - 该字符可以是任何字符(因此
.) - 匹配长度为1个字符,紧跟前一个匹配(因此为
(?!^)\G)。 - 在它之前不应该有单引号,它本身后跟一个空格(因此是
(?<!'(?=\s)),而这是<#39; 回到未来 &#39;部分)。这实际上与\s前面的'不匹配,并且会标记单引号之间包含的字符的结尾。换句话说,结束报价将被标识为单引号,后跟\s。
<强> 2。匹配报价内的内容和结束报价
(?!^)\G(?<!'(?=\s)).
我认为应该在此建立的规则是:
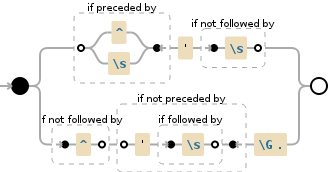
如果您更喜欢图片......
- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?