JavaScript:好的部件regexp.exec(String)说明
我试图了解来自Crockford的JavaScript:The Good Parts的代码示例中发生了什么。
// Break a simple html text into tags and texts.
// (See string.replace for the entityify method.)
// For each tag or text, produce an array containing
// [0] The full matched tag or text
// [1] The tag name
// [2] The /, if there is one
// [3] The attributes, if any
var text = '<html><body bgcolor=linen><p>' +
'This is <b>bold<\/b>!<\/p><\/body><\/html>';
var tags = /[^<>]+|<(\/?)([A-Za-z]+)([^<>]*)>/g;
var a, i;
while ((a = tags.exec(text))) {
for (i = 0; i < a.length; i += 1) {
document.writeln(('// [' + i + '] ' + a[i]).entityify( ));
}
document.writeln( );
}
最难理解&#34; g&#34;全局正在影响正则表达式的解释方式。我也不了解正则表达式。逐行解释会很棒。
4 个答案:
答案 0 :(得分:3)
这是你的正则表达式的一个很好的图表:
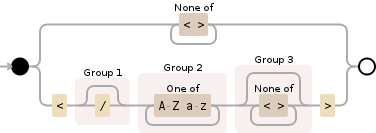
[^<>]+ One or more characters that is not < or > (no tags found)
| or
< Less than sign
(\/?) slash (/), optional
([A-Za-z]+) One or more English letters
([^<>]*) Zero or more non < or > charaters
> Greater than sign
(....)表示它是capture group。使用它们以便您可以提取部分标签。
g标志表示您可以重复执行.exec以获得许多结果。如果没有g标记,则while将进入无限循环。 (基本上它是一步一步.match。)
如果你的正则表达式使用&#34; g&#34; flag,您可以多次使用
exec方法在同一个字符串中查找连续匹配。执行此操作时,搜索将从正则表达式str属性指定的lastIndex子字符串开始。参考:https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/RegExp/exec
对于代码本身,for循环将打印捕获组的匹配文本。例如:
// [0] </b> <-- Matched text (whole tag)
// [1] / <-- Capture group 1, used to capture the slash (closing tag)
// [2] b <-- Capture group 2, used to capture tag name
// [3] <-- Capture group 3, used to capture attributes (if any)
答案 1 :(得分:2)
/ - 启动正则表达式模式
[^<>]+ - 一个或多个不是尖括号的字符(包括换行符)
| - 或
< - 左尖括号
(\/)? - 可选的/(这是捕获组1)
([A-Za-z]+) - 一个或多个字母字符(这是捕获组2)
([^<>]*) - 0个或更多不是尖括号的字符(包括换行符)(这是捕获组3)
> - 直角括号
/g - 结束正则表达式模式并设置将继续匹配的全局修饰符,直到输入结束。
值得注意的是:上面的示例表明评论中第1组和第2组的逆转。
如drjimmie1976所述,regex101是一个很好的资源:example of this regex。
答案 2 :(得分:2)
全局标志不会影响正则表达式的解释方式,但会影响正则表达式的执行方式。如果没有全局标记,exec方法只会找到第一个匹配项,并且说再次调用时没有其他内容,而是在找到所有匹配项之前为每个调用返回新匹配项。
正则表达式:
[^<>]匹配任何非<或>的字符
+是一个量词,意味着前一次匹配一次或多次
|是or运营商
<匹配字符<
(...)用于捕获值
\/?匹配字符/,?是一个量词,表示零或一次
[A-Za-z]+匹配任何一个字母,一次或多次
[^<>]*匹配任何非<或>的字符,零次或多次
>匹配字符>
因此,|之前的部分匹配非HTML标记的代码中的文本,匹配一个HTML标记后的部分,捕获可选的/,标记名称和所有属性。
答案 3 :(得分:1)
/ g开关只是意味着它会在找到第一个匹配后继续搜索匹配。没有它,正则表达式在第一场比赛后停止。
就正则表达本身而言,我不够专家评论。但是http://regex101.com/很棒 - 请查看页面右下角的“快速参考”,输入您自己的参考,然后开始掌握它们。
- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?