重力排序:这可能是以编程方式吗?
我最近一直在考虑在排序算法中使用面向对象的设计。然而,我无法找到一种合适的方法来进一步制作这种在O(n)时间内进行排序的排序算法。
好的,这是我一周以来的想法。我有一组输入数据。我将为每个输入数据分配一个质量(假设输入数据为Mass的类型和Sphere的类型。如果我们假设所有对象都是完美的球形物体,其形状与其质量成比例,最重的一个首先接触地面。我将把所有输入数据放在距离地球相同距离的空间中。我会让他们自由落体。根据引力定律,最重的一个首先击中地面。它们命中的顺序将为我提供排序数据。这在某种程度上很有趣,但在下面我觉得这应该可以使用我迄今为止学到的OO
是否真的可以制作一种使用重力拉动方式的排序技术,还是我愚蠢/疯狂?
编辑:同时关闭所有撞击地面的物体,因此我引入了球形物体概念。
19 个答案:
答案 0 :(得分:20)
问题是,尽管OOP的想法之一可能是对现实世界进行建模,但这并不意味着现实世界中某些东西需要多长时间与多长时间之间存在直接对应关系。用计算机来模拟它。
想象一下您的程序所需的实际步骤:
- 必须为您的数据集中的每个项目构建一个对象。在大多数现代硬件上,仅此一项就需要迭代,因此会使您的策略O(n)处于最佳。
- 需要为每个物体模拟重力的影响。同样,实现这一点的最明显,最直接的方法是迭代。
- 必须捕获每个对象落在编程模型中“地球”表面的时间,并且通过某些特定于实现的机制,相应的对象需要插入到有序列表中作为结果
考虑到这个问题,进一步引入了其他并发症。问问自己:你需要多高才能开始定位这些物体?显然足够高,以便最大的下降;即离地球比最大物体的半径更远。但你怎么知道那是多远?您需要首先确定集合中的最大对象;再次,这将(可能)需要迭代。此外,可以想象这个模拟可能是多线程的,试图模拟物体实际下降的概念的实时行为;但是你会发现自己试图在检测到新碰撞的同时将一个项目添加到一个集合(一项显然需要非零时间的操作)。所以这也会产生线程问题。
简而言之,我无法想象如何在没有特殊硬件的情况下使用OOP正确实现这个想法。也就是说,它真的是一个好主意。事实上,它让我想起Bead Sort - 一种算法虽然与你的想法不一样,但它也是一种利用重力的物理概念的排序解决方案,毫不奇怪,它需要专门的硬件
答案 1 :(得分:9)
你刚刚重申了这个问题。计算引力效应的顺序最多只能是你想要击败的排序算法的O.
答案 2 :(得分:7)
引力计算仅在现实世界中免费。在程序中,您需要对其进行建模。它将是复杂性最小的另一个
答案 3 :(得分:5)
这个想法可能看起来很简单,但在这种情况下,现实世界和模型之间的区别在于,在现实世界中,一切都是并行发生的。要按照您描述的方式对引力排序进行建模,您必须首先将每个对象放在一个单独的线程上,并使用线程安全的方式按照它们完成的顺序将它们添加到列表中。实际上,在排序性能方面,您可能只是对时间进行快速排序,或者因为它们与下降速率处于相同的距离。但是,如果你的公式与质量成比例,你只需跳过所有这些并对质量进行排序。
答案 4 :(得分:5)
通用分类最好是O(n log n)。要改进这一点,您必须了解数据,而不仅仅是如何比较值。
如果值都是数字,radix sorting给出O(n),假设您有数字的上限和下限。这种方法可以扩展到处理任何数字 - 最终,计算机中的所有数据都使用数字表示。例如,您可以在每个传递中对字符串进行基数排序,按一个字符排序,就像它是一个数字一样。
不幸的是,处理可变大小的数据意味着通过基数排序进行可变数量的传递。最终得到O(n log m),其中m是最大值(因为对于无符号,k位给出的值最多为(2 ^ k)-1,对于有符号则为一半)。例如,如果要将整数从0到m-1排序,那么你实际上已经得到了O(n log n)。
将一个问题转换为另一个问题可能是一个非常好的方法,但有时它只是增加了另一层复杂性和开销。
答案 5 :(得分:3)
在虚构的“引力计算机”中,这种排序需要O(1)才能得到解决。但是对于我们所知道的真实计算机,你的横向思想无济于事。
答案 6 :(得分:2)
一旦你计算出他们所有的时间到达地面,你仍然需要对这些值进行排序。你并没有真正获得任何东西,你只需在执行一些额外的不必要的计算后对不同的数字进行排序。
编辑:哎呀。忘了物理101.当然,他们都会在同一时间击中。 :)
任何类似的建模只会将一个排序问题转换为另一个排序问题。你不会得到任何东西。
答案 7 :(得分:2)
忽略其他人提到的所有缺陷,基本上归结为O(n^2)算法,而不是O(n)。您必须遍历所有“球体”,找到“最重”或“最大”的球体,然后将其推入列表,然后冲洗并重复。即,要找到首先击中地面的那个,你必须遍历整个列表,如果它是最后一个,它需要O(n)时间,第二个可能需要O(n-1)等等......但是比这更糟糕的是,你每次只需要计算一些无用的“时间”值就可以执行一系列的数学运算,这样你就可以在第一时间对你感兴趣的值进行排序。
答案 8 :(得分:2)
实际上有一种非常着名的排序算法叫做Spaghetti sort,它与你的类似。 您可以在网上查看一些对它的分析。例如在cstheory。

答案 9 :(得分:2)
Hmmmm。重力排序。
忽略你的特定引力模型是错误的,让我们看看这个想法带给我们的地方。
物理现实有10 ^ 80个处理器。
如果您有N / 2个处理器来排序N个对象,则已知sort的实际下限为log(N)。
如果你有几个可用的CPU核心,你就没有理由不能在几个线程上运行mergesort。
答案 10 :(得分:1)
绝对应该只有你应该支持适当的硬件。否则这听起来很酷。希望有人出示一份IEEE论文,让这个疯狂的梦想可视化。
答案 11 :(得分:1)
来自Debilski's answer的:
我会适应你的想法。我们的确是 有我们的对象,但他们没有区别 重量,但速度。所以,在 开始所有对象都对齐 起跑线和起跑线 拍摄,他们都将与他们一起移动 各种速度到终点。
足够清楚:完成第一个对象 会发出一个信号,说它是 那里。你抓住了信号并写下来 结果论文是谁
我将它进一步简化,并说这些对象是随机正整数。我们希望在它们接近零时按升序对它们进行排序,因此它们与零d的距离最初等于整数本身。
假设模拟是在离散的时间步骤中进行的,即 frames ,在每一帧中,每个对象的新距离都是:d = d - v,当一个对象d ≤ 0时,它将被添加到列表中{ {1}}。这是一个减法和一个条件。每个对象有两个不连续的步骤,因此计算似乎是O(n):线性。
问题是,它只是一帧是线性的!它乘以完成所需的帧数f。模拟本身是O(nf):二次方。
但是,如果我们将帧的持续时间作为参数t,我们就能够以反比例的方式影响帧f的数量。我们可以增加t来减少f,但这是以准确性为代价的,我们增加t越多,两个对象在同一时间范围内完成的概率就越大被列为等价物,即使它们不是。因此,我们得到一个精度可调的算法(就像在大多数有限元模拟环境中一样)
我们可以通过将其转换为自适应+递归算法来进一步完善它。在人类代码中它将是:
function: FESort: arguments: OriginalList, Tolerance
define an empty local list: ResultList
while OriginalList has elements
define an empty local list: FinishedList
iterate through OriginalList
decrement the distance of each object by Tolerance
if distance is less than or equal to zero, move object from OriginalList to FinishedList
check the number of elements in FinishedList
when zero
set Tolerance to double Tolerance
when one
append the only element in FinishedList to ResultList
when more
append the result of FESort with FinishedList and half Tolerance to ResultList
return ResultList
我想知道是否有适合某人的真正类似的实现。
确实有趣的主题:)
PS。上面的伪代码是我对伪代码的想法,如果有的话,请随意以更清晰或更符合的方式重写它。
答案 12 :(得分:1)
如果要构建一台基于某些标准对对象进行排序的计算机(考虑起来并不完全荒谬),那么我认为复杂性的顺序与对象的数量无关,而是与速率无关。重力引起的局部加速度假设它在地球上建模,复杂度将为O(g 0 ),其中g 0 为:
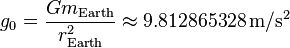
简单的推理是,如果球形物体的中心在开始时对齐,则它们的数量无关紧要(n)。此外,由于重力引起的加速度将随着其增加而具有比高度本身更大的影响。例如,如果我们将所有物体的高度增加10倍,则它们不会花费10倍的时间撞击地面,但要小得多。这包括各种可忽略的近似值,因为加速度实际上取决于两个物体之间的距离,但可以忽略,因为我们对更大的图片而不是特定值更感兴趣。
然而,这是个绝妙的主意。
另外,我喜欢@Jeremy发布的硬币分类视频。最后,面向对象将是我构建这样一台机器时最不关心的问题。更多地考虑它,这是我建造这样一台机器的两分钱:
<击> O 0 o O o
. . . . .
. . . . .
. . . . .
= = = = =
所有对象的大小都与我们要排序的标准成比例。它们最初通过穿过每个球体中心的细杆水平地保持在一起。底部的=专门设计用于在与球体碰撞时在某处记录值(可选地,它们的位置)。在所有球体发生碰撞后,我们将根据记录的值进行排序。
答案 13 :(得分:1)
我会适应你的想法。我们确实有我们的物品,但它们的重量没有差别,但速度不同。因此,在开始时所有物体都在起始线和起始射击上对齐,它们都将以各自的速度移动到终点。
足够清楚:完成后的第一个物体会发出一个信号,说它就在那里。你抓住信号并写信给结果文件。
好的,所以你要模拟它。
我们将您的字段长度设为L=1。步长为∆t时,每个N个对象的移动长度为vᵢ∙∆t。
这意味着每个对象在到达终点前需要sᵢ = L / (vᵢ∙∆t)个步骤。
现在的观点是,为了区分速度非常接近的两个物体,您需要为所有物体设置不同的步长。
现在,在最佳情况下,这意味着对象1在一个步骤中完成,对象2在两个中完成,依此类推。因此,步骤总数为S = 1 + 2 + … + N = N∙(N + 1)/2。这是订单N∙N。
如果不是最好的情况并且速度彼此不相等,则必须降低步长,实际上要重复多次。
答案 14 :(得分:1)
我认为这个问题可以更简单:你想把球体的底部放在不同的高度,这样当相同的重力下降时,最大的将首先击中地面,第二大的第二,等等。相当于使用线而不是球......在这种情况下,你可以说heightOffTheGround = MAX_VALUE - 质量。
你也不需要担心随着时间的推移加速...因为你不关心它们的速度或物理现实,你可以给它们所有的初始速度x,并从那里开始。
问题是,我们基本上只是重述了问题并像这样解决了它(伪代码):
int[] sortedArray; // empty
int[] unsortedArray; // full of stuff
int iVal = MAX_INT_VALUE;
while (true)
{
foreach (currentArrayValue in sortedArray)
{
if (iVal = current array value
{
put it in my sortedArray
remove the value from my unsortedArray
}
}
if (unsortedArray is empty)
{
break; // from while loop
}
iVal--
}
问题是要运行物理引擎,你必须迭代每个时间单位,这将是O(1)...具有非常大常量...系统将运行的恒定delta值。缺点是,对于绝大多数这些delta值,你基本上都没有接近答案:在任何给定的迭代中,很可能所有的球体/线条/任何东西都会移动......但是没有会打。
你可以试着说,好吧,让我们跳过很多中间步骤,然后直到一个点击!但这意味着您必须知道哪一个是最大的...并且您又回到了排序问题。
答案 15 :(得分:1)
几周前,我在想同样的事情。
我想用Phys2D库来实现它。它可能不实用,但只是为了好玩。您还可以为对象指定负权重以表示负数。使用phys2d库可以定义重力,因此具有负重量的物体将进入屋顶,具有正重量的物体将落下。然后在地板和屋顶之间的中间布置所有物体,地板和屋顶之间的距离相同。假设你有一个结果数组r []长度=对象数。然后每当一个物体接触到屋顶时,你将它添加到数组r [0]的开头并递增计数器,下次物体接触屋顶时你将它添加到r [1],每当一个物体到达地面时你将它添加到数组r [r.length-1]的末尾,下次将其添加到r [r.length-2]。最后,没有移动的物体(在中间保持浮动)可以添加到数组的中间(这些物体是0)。
效率不高,但可以帮助您实现自己的想法。
答案 16 :(得分:1)
我喜欢这个主意!这很聪明。虽然是其他人所说的一般正确,但O(n log n)界限一般是排序问题的可证明的下限,我们需要记住,下限是仅适用于基于比较的模型。你在这里提出的是一个完全不同的模型,它值得进一步思考。
另外,正如詹姆斯和马克斯所指出的那样,较重的一个并不比较轻的一个旅行得快,你显然需要使模型适应较重的物体(数量)确实会更快/更远的地方(或者更慢/更少)这样你就能以某种方式区分数字(离心机也会浮现在脑海中)。
需要更多思考,但你的想法很敏锐!
(编辑) 现在看看恩里克的Phys2D想法,我觉得它更有意义。
我建议的一件事就是明确忽略效率方面。 (我知道,我知道那是整个目标)。这是一个新模型,我们首先需要弥合这个想法及其实现之间的差距。只有这样,我们才能理解时间复杂度对这个模型的意义。
答案 17 :(得分:0)
- 我相信很高兴提及/参考:What is the relation
between P vs. NP and Nature's ability to solve NP problems
efficiently?
排序是
O(nlog(n)),为什么不尝试解决NP难问题? - 根据物理定律,物体的比例会下降 gravitational constant质量可以忽略不计。
- 模拟物理过程会影响实际的时间复杂度。
答案 18 :(得分:0)
分析: (1)所有球体中心在开始时对齐 (2)更大的数字==&gt;质量更高==&gt; radius greater ==&gt;到地面的距离较低 (3)真空&#39;相同的加速度=相同的速度演变==&gt;中心的距离相同==&gt;如何更大的半径...球体将如何更早地撞击地面 ==&GT;从概念上来说还可以,良好的物理技术如果球体撞到地面时它可以发送识别信号+命中时间......这将给出排序列表 实际上......不是一个好的&#39;数字技术
- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?