匹配不是某个字符
我有一个简单的函数,它从字符串中产生至少gapSize连续N的所有延伸:
def get_gap_coordinates(sequence, gapSize=25):
gapPattern = "N{"+str(gapSize)+",}"
p = re.compile(gapPattern)
m = p.finditer(sequence)
for gap in m:
start,stop = gap.span()
yield(start,stop)
现在我希望有一个完全相反的功能:匹配至少为gapSize N' s的非连续延伸的所有字符。这些延伸可能出现在字符串中的任何位置(开头,中间和结尾),任何给定的数字。
我已经研究过外观并尝试了
(?!N{25,}).*
但这并不能满足我的需要。 非常感谢任何帮助!
编辑: 例如:序列NNNNNNACTGACGTNNNACTGACNNNNN应匹配ACTGACGTNNNACTGAC,用于gapSize = 5和ACTGACGT& ACTGAC for gapSize = 3.
4 个答案:
答案 0 :(得分:2)
所以这是一个纯正则表达式解决方案,它似乎是你想要的,但我想知道是否有更好的方法来做到这一点。当我想出它们时,我会添加替代品。我使用了几个在线正则表达式工具以及在shell中玩游戏。
One of the tools有一个很好的正则表达式和facilty图形生成SO答案代码:正则表达式(差距为10)是:
^.*?(?=N{10})|(?<=N{10})[^N].*?(?=N{10})|(?<=N{10})[^N].*?$
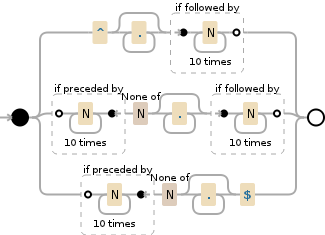
用法:
s = 'NAANANNNNNNNNNNBBBBNNNCCNNNNNNNNNNDDDDN'
def foo(s, gapSize = 25):
'''yields non-gap items (re.match objects) in s or
if gaps are not present raises StopIteration immediately
'''
# beginning of string and followed by a 'gap' OR
# preceded a 'gap' and followed by a 'gap' OR
# preceded a 'gap' and followed by end of string
pattern = r'^.*?(?=N{{{}}})|(?<=N{{{}}})[^N].*?(?=N{{{}}})|(?<=N{{{}}})[^N].*?$'
pattern = pattern.format(gapSize, gapSize, gapSize, gapSize)
for match in re.finditer(pattern, s):
#yield match.span()
yield match
for match in foo(s, 10):
print match.span(), match.group()
'''
>>>
(0, 5) NAANA
(15, 24) BBBBNNNCC
(34, 39) DDDDN
>>>
'''
因此,如果你仔细想一下,你会发现 gap 的开头是 non-gap 的结尾,反之亦然。因此,使用简单的正则表达式:迭代间隙,向循环添加逻辑以跟踪非间隙跨度和yield跨度。 (我的占位符变量名可能会得到改进)
s = 'NAANANNNNNNNNNNBBBBNNNCCNNNNNNNNNNDDDDN'
def bar(s, n):
'''Yields the span of non-gap items in s or
immediately raises StopIteration if gaps are not present.
'''
gap = r'N{{{},}}'.format(n)
# initialize the placeholders
previous_start = 0
end = len(s)
for match in re.finditer(gap, s):
start, end = match.span()
if start == 0:
previous_start = end
continue
end = start
yield previous_start, end
previous_start = match.end()
if end != len(s):
yield previous_start, len(s)
用法
for start, end in bar(s, 4):
print (start, end), s[start:end]
'''
>>>
(0, 5) NAANA
(15, 24) BBBBNNNCC
(34, 39) DDDDN
>>>
'''
答案 1 :(得分:1)
我想到正则表达式直接匹配想要的块,但没有什么好的想法。我认为最好继续找到间隙并简单地使用间隙坐标来获得良好的块坐标。我的意思是,它们基本相同,对吧?间隙停止是块开始,间隙开始是块停止。
def get_block_coordinates(sequence, gapSize=25):
gapPattern = "N{"+str(gapSize)+",}"
p = re.compile(gapPattern)
m = p.finditer(sequence)
prevStop = 0
for gap in m:
start,stop = gap.span()
if start:
yield(prevStop,start)
prevStop = stop
if prevStop < len(sequence):
yield(prevStop,len(sequence))
答案 2 :(得分:1)
否定前瞻似乎工作正常。例如。对于gap-size 3,regexp将是:
N{3,}?([^N](?:(?!N{3,}?).)*)
试试here。
import re
def get_gap_coordinates(sequence, gapSize=25):
gapPattern = "N{%s,}?([^N](?:(?!N{%s,}?).)*)" % (gapSize, gapSize)
p = re.compile(gapPattern)
m = p.finditer(sequence)
for gap in m:
start,stop = gap.start(1), gap.end(1)
yield(start,stop)
for x in get_gap_coordinates('NNNNNNACTGACGTNNNACTGACNNNNN', 3):
print x
警告:如果字符串不以“N”序列开头,则在字符串的开头可能不匹配。但是你总是可以用左边的间隙大小'N'填充字符串。
答案 3 :(得分:0)
我认为你可以这样做:
gapPattern = "(N{"+str(gapSize)+",})"
p = re.compile(gapPattern)
i = 0
for s in re.split(p, sequence):
if not re.match(p, s):
yield i
i += len(s)
根据re.split函数,它会生成一系列不符合gap_size "N"个字符的子串的偏移量。
- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?