жҲ‘е·Із»ҸдёҺTesseractдёҖиө·еҠӘеҠӣдәүеҸ–еҗ„з§ҚOCRйЎ№зӣ®пјҢжҲ‘д»ҠеӨ©еҸ‘зҺ°дәҶдёҖдёӘз”ЁдҫӢпјҢжҲ‘и®ӨдёәиҝҷдјҡжҳҜдёҖдёӘжүЈзҜ®пјҢдҪҶз»ҸиҝҮеҮ дёӘе°Ҹж—¶жҲ‘д»Қ然дёҚж»Ўж„ҸгҖӮжҲ‘жғіеңЁиҝҷйҮҢжҸҗеҮәй—®йўҳпјҢзңӢзңӢжҳҜеҗҰжңүе…¶д»–дәәе°ұеҰӮдҪ•и§ЈеҶіиҝҷдёӘй—®йўҳжҸҗеҮәдәҶе»әи®®гҖӮ
жҲ‘зҡ„еҰ»еӯҗд»ҠеӨ©ж—©дёҠжқҘжүҫжҲ‘并иҜўй—®жҳҜеҗҰжңүеҘ№еҸҜд»ҘиҪ»жқҫжү«жҸҸжІғе°”зҺӣзҡ„收жҚ®пјҢ并йҡҸзқҖж—¶й—ҙзҡ„жҺЁз§»е»әз«ӢдәҶзұ»еҲ«е’Ңзү№е®ҡйЎ№зӣ®зҡ„д»·ж јеҺҶеҸІи®°еҪ•пјҢд»ҘдҫҝжҲ‘们еҸҜд»ҘиҪ»жқҫең°еҒҡдёҖдәӣи¶ӢеҠҝж·ұе…Ҙз ”з©¶ж”ҜеҮәзҡ„жқҘжәҗгҖӮиө·еҲқжҲ‘и§үеҫ—иҝҷжҳҜдёҖдёӘйқһеёёй«ҳзҡ„и®ўеҚ•пјҢдҪҶеңЁеҒҡдәҶдёҖдәӣжҢ–жҺҳд№ӢеҗҺпјҢжҲ‘еҸ‘зҺ°дәҶдёҖдәӣи®©жҲ‘и§үеҫ—иҝҷжҳҜи§ҰжүӢеҸҜеҸҠзҡ„дәӢжғ…пјҡ
жІғе°”зҺӣ收жҚ®дёҖиҲ¬пјҢз»“жһ„еҗҲзҗҶпјҢжҳ“дәҺйҳ…иҜ»гҖӮ他们з”ҡиҮіеҢ…жӢ¬жҜҸдёӘйЎ№зӣ®зҡ„UPCпјҲеҸҜиғҪеҜ№UPCж•°жҚ®еә“иҝӣиЎҢжҹҘжүҫпјҹпјү并且似д№Һз”ЁFжҲ–IеҜ№йЈҹе“ҒиҝӣиЎҢеҲҶзұ»пјҲдёҚзЎ®е®ҡеҢәеҲ«жҳҜд»Җд№Ҳпјү并且иҝҳжңүдёҖдёӘзЁҺжі•д»Јз ҒеҲ—пјҢиҝҷеҸҜиғҪиҜҒжҳҺжҳҜжңүз”Ёзҡ„жҲ‘дәҶи§ЈдәҶд»Јз Ғеҗ«д№үзҡ„з§ҳеҜҶгҖӮ
жҲ‘иҝӣдёҖжӯҘеҸ‘зҺ°пјҢжҲ‘еҸҜд»ҘиҺ·еҫ—жҹҗз§ҚжІғе°”зҺӣйЎ№зӣ®жҹҘжүҫAPIпјҢиҝҷеҜ№дәҺUPCжҹҘжүҫйқһеёёжңүз”ЁгҖӮ
他们жңүдёҖдёӘжҷәиғҪжүӢжңәеә”з”ЁзЁӢеәҸпјҢеҸҜи®©жӮЁжү«жҸҸжҜҸеј ж”¶жҚ®дёҠжү“еҚ°зҡ„дәҢз»ҙз ҒгҖӮиҜҘеә”з”ЁзЁӢеәҸжҹҘжүҫпјҶпјғ34; TCпјҶпјғ34;д»Јз Ғе…ій—ӯ收жҚ®е№¶д»ҺжңҚеҠЎеҷЁдёӯжҸҗеҸ–ж•ҙдёӘйҖҗ项收жҚ®гҖӮе®ғеҗ‘жӮЁжҳҫзӨә收жҚ®зҡ„дјҳз§ҖеӣҫеҪўиЎЁзӨәпјҢеҢ…жӢ¬жүҖжңүйЎ№зӣ®зҡ„зј©з•Ҙеӣҫе’ҢжҲҗжң¬зӯүгҖӮеҰӮжһңжӯӨеә”з”ЁзЁӢеәҸеҸӘжҳҜеҲҶзұ»е’ҢжұҮжҖ»ж”¶жҚ®пјҢжҲ‘дјҡе®ҢжҲҗпјҒдҪҶжҳҜпјҢе”үпјҢиҝҷдёҚжҳҜеә”з”ЁзЁӢеәҸзҡ„зӣ®зҡ„....
жңҖеҗҺдёҖдёӘйҡҫйўҳжҳҜжӮЁеҸҜд»ҘеҜјеҮәи®Ўз®—жңәз”ҹжҲҗзҡ„收жҚ®зҡ„PNGеӣҫеғҸпјҢд»ҘйҳІжӮЁжғіиҰҒдҝқеӯҳ并жү”жҺүзәёиҙЁзүҲжң¬гҖӮиҝҷеҜ№жҲ‘иҖҢиЁҖе°ұжҳҜжӢҚж‘„зҡ„й’ұпјҢеӣ дёәиҝҷдәӣPNGжҳҜз”ұи®Ўз®—жңәеҲӣе»әзҡ„пјҢеӣ жӯӨдёҚдјҡеҸ—еҲ°еӣҙз»•жӢҚз…§жҲ–жү«жҸҸзәёиҙЁж”¶жҚ®зҡ„й—®йўҳзҡ„еҪұе“Қ
е…¶дёӯдёҖдёӘзӨәдҫӢпјҲзЁҚеҫ®зј–иҫ‘д»Ҙж·ЎеҢ–жҹҗдәӣеҢәеҹҹпјҢдҪҶе…¶д»–ж–№йқўдёҺеә”з”ЁзЁӢеәҸе®Ңе…ЁзӣёеҗҢпјүеңЁжӯӨеӨ„пјҡ
https://postimg.cc/image/s56o0wbzf/
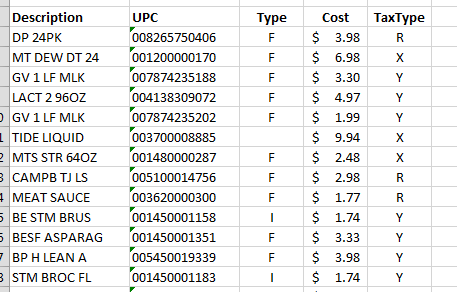
дҪ еҸҜд»ҘзңӢеҲ°ж–Үжң¬зҡ„йҮҚиҰҒйғЁеҲҶе®Ңе…ЁеҜ№йҪҗеңЁ5еҲ—дёӯпјҢиҝҷжңҖз»ҲжҳҜиҝҷдёӘй—®йўҳзҡ„еҶ…е®№гҖӮеҰӮдҪ•и®©TesseractеҮҶзЎ®ең°е°Ҷе…¶иҪ¬жҚўжҲҗж–Үжң¬гҖӮжҲ‘жңүеҫҲеӨҡжғіжі•д»ҺиҝҷйҮҢејҖе§ӢпјҢдҪҶдёҖеҲҮйғҪд»ҺOCRејҖе§ӢпјҒ
жҲ‘жңҖдәІиҝ‘зҡ„е°ұжҳҜиҝҷдёӘдҫӢеӯҗпјҡ
жҲ‘дҪҝз”ЁдәҶpsm6е’ҢдёҖдёӘеӯ—з¬ҰйҷҗеҲ¶йӣҶжқҘејәеҲ¶е®ғеҸӘеҒҡеӨ§еҶҷ+ж•°еӯ—+еҮ дёӘз¬ҰеҸ·пјҡ
tessedit_char_whitelist 0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ#()/*@%-.
жҲ‘е°қиҜ•еҜ№еӣҫеғҸиҝӣиЎҢдёҖдәӣйў„еӨ„зҗҶпјҢд»ҘеҠ еҺҡеӯ—з¬ҰпјҢ并确дҝқе®ғзҡ„зәҜй»‘иүІе’ҢзҷҪиүІпјҢдҪҶжҲ‘зҡ„еҠӘеҠӣжІЎжңүжҜ”жІғе°”зҺӣ+дёҠйқўзҡ„еҺҹе§ӢеӣҫеғҸжӣҙжҺҘиҝ‘е‘Ҫд»ӨгҖӮ
зҗҶжғіжғ…еҶөдёӢпјҢеӣ дёәиҝҷжҳҜдёҖдёӘз»“жһ„иүҜеҘҪзҡ„PNGпјҢеҰӮжһңжҲ‘еҸҜд»ҘжҢүеғҸзҙ е®ҪеәҰе®ҡд№үеҲ—пјҢжҲ‘еёҢжңӣе®ғжҖ»жҳҜе®ҪеәҰзӣёеҗҢпјҢд»ҘдҫҝTesseractеҸҜд»ҘзӢ¬з«Ӣең°еӨ„зҗҶжҜҸдёҖеҲ—гҖӮжҲ‘иҜ•еӣҫеҜ№жӯӨиҝӣиЎҢз ”з©¶пјҢдҪҶжҲ‘жүҖи§ҒиҝҮзҡ„UZNж–Ү件并没жңүеғҸзҙ е®ҪеәҰйӮЈж ·зҝ»иҜ‘з»ҷжҲ‘пјҢзңӢиө·жқҘй«ҳеәҰжҳҜдёҖдёӘеӣ дёәй«ҳеәҰдёҚй«ҳиҖҢж— жі•и§ЈеҶіиҝҷдәӣй—®йўҳзҡ„еӣ зҙ гҖӮж°ёиҝңйғҪжҳҜеҸҳж•°гҖӮ
еҸҰеӨ–пјҢжҲ‘йңҖиҰҒеј„жё…жҘҡеҰӮдҪ•и®ӯз»ғTesseractеҮҶзЎ®ең°иҜҶеҲ«ж•°еӯ—100пј…пјҲиҝҷдәӣеӯ—жҜҚ并дёҚжҳҜйқһеёёйҮҚиҰҒпјүгҖӮжҲ‘ејҖе§Ӣз ”з©¶еҰӮдҪ•и®ӯз»ғиҜҘзЁӢеәҸпјҢдҪҶиҜҙе®һиҜқпјҢе®ғеҫҲеҝ«е°ұи¶…еҮәдәҶжҲ‘зҡ„еӨҙи„‘пјҢеӣ дёәж–ҮжЎЈдёӯзҡ„еҹ№и®ӯиҢғеӣҙжӣҙеӨҡзҡ„жҳҜи®©е®ғиҜҶеҲ«ж•ҙдёӘиҜӯиЁҖиҖҢдёҚд»…д»…жҳҜ10дҪҚж•°гҖӮ
з»ҲжһҒжёёжҲҸи§ЈеҶіж–№жЎҲе°ҶжҳҜдёҖдёӘз®ЎйҒ“иҝһй”Ғе‘Ҫд»ӨпјҢе®ғд»Һеә”з”ЁзЁӢеәҸдёӯиҺ·еҸ–еҺҹе§ӢPNGпјҢ并д»Һ收жҚ®зҡ„йҮҚиҰҒйғЁеҲҶиҝ”еӣһдёҖдёӘеҢ…еҗ«5еҲ—ж•°жҚ®зҡ„CSVгҖӮжҲ‘дёҚеёҢжңӣеҮәзҺ°иҝҷдёӘй—®йўҳпјҢдҪҶжҳҜжҲ‘е°Ҷйқһеёёж„ҹи°ўд»»дҪ•жҢҮеҜјжҲ‘зҡ„её®еҠ©пјҒеңЁиҝҷдёҖзӮ№дёҠпјҢжҲ‘еҸӘжҳҜи§үеҫ—еҶҚж¬Ўиў«Tesseractйһӯжү“пјҢжүҖд»ҘжҲ‘еҶіеҝғжүҫеҲ°дёҖз§Қж–№жі•жқҘжҺҢжҸЎеҘ№пјҒ
зӯ”жЎҲ 0 :(еҫ—еҲҶпјҡ14)
жҲ‘жңҖз»Ҳе®Ңе…Ёжё…йҷӨдәҶиҝҷдёҖзӮ№пјҢ并еҜ№з»“жһңйқһеёёж»Ўж„ҸжүҖд»ҘжҲ‘жғіжҲ‘дјҡеҸ‘еёғе®ғд»ҘйҳІе…¶д»–дәәеҸ‘зҺ°е®ғжңүз”ЁгҖӮ
жҲ‘жІЎжңүеҝ…иҰҒиҝӣиЎҢд»»дҪ•еӣҫеғҸеҲҶеүІпјҢиҖҢжҳҜдҪҝз”ЁжӯЈеҲҷиЎЁиҫҫејҸпјҢеӣ дёәжІғе°”зҺӣзҡ„收жҚ®жҳҜеҰӮжӯӨеҸҜйў„жөӢгҖӮ
жҲ‘еңЁWindowsдёҠпјҢжүҖд»ҘжҲ‘еҲӣе»әдәҶдёҖдёӘPowerShellи„ҡжң¬жқҘиҝҗиЎҢиҪ¬жҚўе‘Ҫд»Өе’ҢжӯЈеҲҷиЎЁиҫҫејҸжҹҘжүҫпјҶamp;жӣҝжҚўпјҡ
# -----------------------------------------------------------------
# Script: ParseReceipt.ps1
# Author: Jim Sanders
# Date: 7/27/2015
# Keywords: tesseract OCR ImageMagick CSV
# Comments:
# Used to convert a Wal-mart receipt image to a CSV file
# -----------------------------------------------------------------
param(
[Parameter(Mandatory=$true)] [string]$image
) # end param
# create output and temporary files based on input name
$base = (Get-ChildItem -Filter $image -File).BaseName
$csvOutfile = $base + ".txt"
$upscaleImage = $base + "_150.png"
$ocrFile = $base + "_ocr"
# upscale by 150% to ensure OCR works consistently
convert $image -resize 150% $upscaleImage
# perform the OCR to a temporary file
tesseract $upscaleImage -psm 6 $ocrFile
# column headers for the CSV
$newline = "Description,UPC,Type,Cost,TaxType`n"
$newline | Out-File $csvOutfile
# read in the OCR file and write back out the CSV (Tesseract automatically adds .txt to the file name)
$lines = Get-Content "$ocrFile.txt"
Foreach ($line in $lines) {
# This wraps the 12 digit UPC code and the price with commas, giving us our 5 columns for CSV
$newline = $line -replace '\s\d{12}\s',',$&,' -replace '.\d+\.\d{2}.',',$&,' -replace ',\s',',' -replace '\s,',','
$newline | Out-File -Append $csvOutfile
}
# clean up temporary files
del $upscaleImage
del "$ocrFile.txt"
з”ҹжҲҗзҡ„ж–Ү件йңҖиҰҒеңЁExcelдёӯжү“ејҖпјҢ然еҗҺиҝҗиЎҢtext to columnsеҠҹиғҪпјҢд»Ҙдҫҝе®ғдёҚдјҡйҖҡиҝҮиҮӘеҠЁе°Ҷе®ғ们иҪ¬жҚўдёәж•°еӯ—жқҘз ҙеқҸUPCд»Јз ҒгҖӮиҝҷжҳҜдёҖдёӘжҲ‘дёҚдјҡж·ұе…Ҙз ”з©¶зҡ„дј—жүҖе‘ЁзҹҘзҡ„й—®йўҳпјҢдҪҶжҳҜжңүеҫҲеӨҡж–№жі•еҸҜд»ҘеӨ„зҗҶпјҢжҲ‘йҮҮз”ЁдәҶиҝҷз§ҚзЁҚеҫ®жӣҙеҠ жүӢеҠЁзҡ„ж–№ејҸгҖӮ
жҲ‘жңҖе№ёзҰҸзҡ„жҳҜжңҖз»Ҳеҫ—еҲ°дёҖдёӘз®ҖеҚ•зҡ„.csvжҲ‘еҸҜд»ҘеҸҢеҮ»дҪҶжҳҜжҲ‘жүҫдёҚеҲ°дёҖдёӘеҫҲеҘҪзҡ„ж–№жі•жқҘеҒҡеҲ°иҝҷдёҖзӮ№иҖҢдёҚдјҡз ҙеқҸUPCд»Јз Ғз”ҡиҮіжӣҙеғҸжҳҜз”Ёиҝҷз§Қж јејҸеҢ…иЈ…е®ғ们пјҡ
"=""12345"""
иҝҷзЎ®е®һжңүж•ҲдҪҶжҲ‘еёҢжңӣUPCд»Јз ҒеҸӘжҳҜExcelдёӯзҡ„ж–Үжң¬ж•°еӯ—пјҢд»ҘйҳІжҲ‘д»ҘеҗҺиғҪеӨҹеҜ№Wal-mart APIиҝӣиЎҢжҹҘжүҫгҖӮ
ж— и®әеҰӮдҪ•пјҢиҝҷжҳҜ他们зңӢеҫ…еҜје…Ҙе’Ңеҝ«йҖҹж јејҸеҢ–зҡ„ж–№ејҸпјҡ
https://s3.postimg.cc/b6cjsb4bn/Receipt_Excel.png
жҲ‘д»Қ然йңҖиҰҒеҜ№дёҚжҳҜи®ўеҚ•йЎ№зҡ„иЎҢиҝӣиЎҢдёҖдәӣеһғеңҫжё…зҗҶпјҢдҪҶиҝҷеҸӘйңҖиҰҒеҮ з§’й’ҹпјҢжүҖд»ҘдёҚдјҡжү“жү°жҲ‘еӨӘеӨҡгҖӮ
ж„ҹи°ў@RevJohnеңЁжӯЈзЎ®ж–№еҗ‘дёҠзҡ„жҺЁеҠЁпјҢжҲ‘дёҚдјҡжғіеҲ°еҸӘжҳҜз®ҖеҚ•ең°зј©ж”ҫеӣҫеғҸпјҢдҪҶиҝҷеңЁдё–з•ҢдёҠдёҺTesseractжңүжүҖдёҚеҗҢпјҒ
зӯ”жЎҲ 1 :(еҫ—еҲҶпјҡ11)
收жҚ®дёҠзҡ„ж–Үеӯ—иҜҶеҲ«жҳҜOCRиҰҒеӨ„зҗҶзҡ„жңҖйҡҫзҡ„й—®йўҳд№ӢдёҖгҖӮ
еҺҹеӣ еҫҲеӨҡпјҡ
жӮЁжңҖеҘҪзҡ„йҖүжӢ©жҳҜжү§иЎҢд»ҘдёӢж“ҚдҪңпјҡ
жңҖеҘҪйҖҡиҝҮеҲҶжһҗз»“жһңзҡ„еҮ дҪ•еӣҫеҪўиҖҢдёҚжҳҜжӯЈеҲҷиЎЁиҫҫејҸжқҘжү§иЎҢеёғеұҖгҖӮеҰӮжһңOCRжңүй”ҷиҜҜпјҢеҲҷжӯЈеҲҷиЎЁиҫҫејҸжңүй—®йўҳгҖӮдҫӢеҰӮпјҢдҪҝз”ЁеҮ дҪ•дҪ“пјҢдҪ еҸҜд»ҘжүҫеҲ°дёҖдёӘеҫҲеҘҪзҡ„UPCеҸ·з ҒеҖҷйҖүиҖ…пјҢеңЁи§’иүІзҡ„дёӯеҝғз”»дёҖжқЎзәҝпјҢ然еҗҺдҪ е°ұзҹҘйҒ“е“ӘдёӘд»·ж јеұһдәҺйӮЈдёӘUPCгҖӮ
жӯӨеӨ–пјҢдёҖдәӣе•Ҷдёҡи§ЈеҶіж–№жЎҲе…·жңү收жҚ®жү«жҸҸзҡ„иҮӘе®ҡд№үеҠҹиғҪпјҢз”ҡиҮіеҸҜд»ҘеңЁз§»еҠЁи®ҫеӨҮдёҠеҝ«йҖҹиҝҗиЎҢгҖӮ
жҲ‘жӯЈеңЁдёҺд№ӢеҗҲдҪңзҡ„е…¬еҸёMicroBlinkпјҢжңүOCR moduleдёӘ移еҠЁи®ҫеӨҮгҖӮеҰӮжһңжӮЁдҪҝз”Ёзҡ„жҳҜiOSпјҢеҲҷеҸҜд»ҘдҪҝз”ЁCocoaPodsиҪ»жқҫе°қиҜ•
pod try PPBlinkOCR
{kind=link}