使用字符串中的首字母分隔名称
我一直试图将名字与句子分开,但我没有用正则表达式(我是新手)这样做
我使用了以下names = re.findall(r'[A-Z][a-z]*',string)
但它提供了类似['John', 'H', 'Watson', 'Sir', 'Arthur', 'Ignatius', 'Conan', 'Doyle']的输出,我试图让它像['John H. Watson', 'Sir Arthur Ignatius Conan Doyle']
代码:的
string = "John H. Watson is not real but Sir Arthur Ignatius Conan Doyle is"
names = re.findall(r'[A-Z][a-z]*',string)
print names
响应:
['John', 'H', 'Watson', 'Sir', 'Arthur', 'Ignatius', 'Conan', 'Doyle']
2 个答案:
答案 0 :(得分:2)
对于您的示例,此正则表达式将起作用:
>>> print re.findall(ur'(?:\b[A-Z][a-z]*\W+)*[A-Z][a-z]*\b', string)
['John H. Watson', 'Sir Arthur Ignatius Conan Doyle']
然而,对于许多边缘情况,名称可能非常复杂。
答案 1 :(得分:0)
继续使用你的正则表达式,你会发现它会匹配以大写和单独匹配开头的任何单词。我想你想做更多的事情:
(?:\s?\b[A-Z][a-z\.]*)+
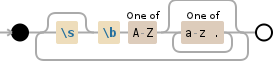
这将重复匹配,直到一个非名字'出现(即一个不大写的单词)。
问题在于显然会出现与非姓名相匹配的情况。我能想到的一个问题是如果一个句子以非名字开头而第二个单词是一个名字,它将包括第一个单词将包含在匹配中。例如,亚瑟爵士'将包括The。关于此正则表达式的好处是,可以通过取消McDonald令牌来匹配\b之类的名称。
相关问题
最新问题
- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?