如何组合这两个正则表达式? (带和不带撇号的单词)
我正在尝试构建一个正则表达式来捕获字符串中的每个单词(包括撇号),如下所示:
Despite trying and trying I haven't found a regex to capture all these words
但我希望它忽略'''之类的字词,并从word读取words',从cause读取'cause;即撇号必须在文本中。
我有以下两个表达式:
[a-z]+'[a-z]+
[a-z]+
我假设他们可以通过一个简单的运算符加入,但我无法找出该运算符可能是什么。
3 个答案:
答案 0 :(得分:1)
试试这个:
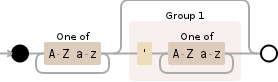
(\w+'\w+)|(\w+)
上述内容仍然包含words'和'cause,但没有撇号。
答案 1 :(得分:1)
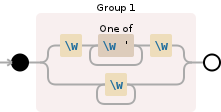
答案 2 :(得分:0)
使用群组和“?”优雅,应该是最快的实施。以下表达式不仅限于python,而是适用于任何接受扩展正则表达式的工具。我也不确定你想用数字做什么(另一个原因是“\ w”没有在答案中使用):
[A-ZA-Z] +('[A-ZA-Z] +)?
$ str="Despite trying and trying I haven't found a regex to capture all these words... 'cause"
$ echo "$str" | sed -r "s/[A-Za-z]+('[A-Za-z]+)?/MATCH/g"
MATCH MATCH MATCH MATCH MATCH MATCH MATCH MATCH MATCH MATCH MATCH MATCH MATCH MATCH... 'MATCH
$ echo "$str" | awk "{ gsub(/[A-Za-z]+('[A-Za-z]+)?/,\"MATCH\") } 1"
MATCH MATCH MATCH MATCH MATCH MATCH MATCH MATCH MATCH MATCH MATCH MATCH MATCH MATCH... 'MATCH
这是来自www.debuggex.com的漂亮图表......
基本正则表达式增加了几个:
[A-ZA-Z] \ + \('[A-ZA-Z] \ + \)\?
如果您有POSIX字符类:
EXTENDED:
[[:阿尔法:]] +('[[:阿尔法:]] +)?
BASIC:
[[:阿尔法:]] \ + \('[[:阿尔法:]] \ + \)?\
相关问题
最新问题
- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?