ňťĘPythonň║ôStatsmodelsńŞş´╝îŠéĘňĆ»ń╗ąńŻ┐šöĘprint(results.summary())ŠëôňŹ░ňç║ňŤ×ňŻĺš╗ôŠ×ť´╝îňŽéńŻĽňťĘńŞÇńެŔíĘŠá╝ńŞşŠëôňŹ░ňç║ňĄÜńެňŤ×ňŻĺšÜäŠĹśŔŽü´╝îń╗ąńż┐ŠŤ┤ňąŻňť░Ŕ┐ŤŔíöŔżâ´╝č
š║┐ŠÇžňŤ×ňŻĺ´╝îń╗úšáüňĆľŔç¬statsmodelsŠľçŠíú´╝Ü
nsample = 100
x = np.linspace(0, 10, 100)
X = np.column_stack((x, x**2))
beta = np.array([0.1, 10])
e = np.random.normal(size=nsample)
y = np.dot(X, beta) + e
model = sm.OLS(y, X)
results_noconstant = model.fit()
šäÂňÉÄŠłĹňÉĹŠĘíň×őŠĚ╗ňŐáńŞÇńެňŞŞÚçĆň╣Âň揊ČíŔ┐ÉŔíîňŤ×ňŻĺ´╝Ü
beta = np.array([1, 0.1, 10])
X = sm.add_constant(X)
y = np.dot(X, beta) + e
model = sm.OLS(y, X)
results_withconstant = model.fit()
ŠłĹňŞîŠťŤňťĘńŞÇň╝áŔíĘŠá╝ńŞşšťőňł░results_noconstantňĺîresults_withconstantšÜäŠĹśŔŽüŃÇéŔ┐Öň║öŔ»ąŠś»ńŞÇńŞ¬ÚŁ×ňŞŞŠťëšöĘšÜäňŐčŔ⯴╝îńŻćŠłĹňťĘstatsmodelsŠľçŠíúńŞşŠ▓튝ëŠëżňł░ń╗╗ńŻĽšŤŞňů│Ŕ»┤ŠśÄŃÇé
š╝ľŔżĹ´╝ÜŠłĹŠâ│ňł░šÜäňŤ×ňŻĺŔíĘš▒╗ń╝╝ń║Äthis´╝Ŋâ│ščąÚüôŠś»ňÉŽŠťëšÄ░ŠłÉšÜäňŐčŔ⯊ŁąŠëžŔíĄŠôŹńŻťŃÇé
šşöŠíł 0 :(ňżŚňłć´╝Ü6)
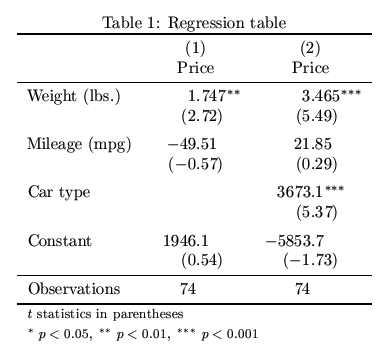
Šťësummary_col´╝çŠíúńŞşń╗Źšäš╝║ň░ĹAFAIRŃÇé
ŠłĹŔ┐śŠ▓튝뚝芺úň░ŁŔ»ĽŔ┐ç´╝îńŻćŠłĹń╗ÄńŞÇńŞ¬ÚŚ«ÚóśńŞşŠëżňł░ń║ćńŞÇńެšŤŞňů│šÜäńżőňşÉŠŁąňłáÚÖĄńŞÇń║ŤÔÇťŔ«ĘňÄîšÜäÔÇŁňĆ銼░ŃÇé
"""
mailing list, and issue https://github.com/statsmodels/statsmodels/pull/1638
"""
import pandas as pd
import numpy as np
import string
import statsmodels.formula.api as smf
from statsmodels.iolib.summary2 import summary_col
df = pd.DataFrame({'A' : list(string.ascii_uppercase)*10,
'B' : list(string.ascii_lowercase)*10,
'C' : np.random.randn(260),
'D' : np.random.normal(size=260),
'E' : np.random.random_integers(0,10,260)})
m1 = smf.ols('E ~ D',data=df).fit()
m2 = smf.ols('E ~ D + C',data=df).fit()
m3 = smf.ols('E ~ D + C + B',data=df).fit()
m4 = smf.ols('E ~ D + C + B + A',data=df).fit()
print(summary_col([m1,m2,m3,m4]))
ń╗ŹŠťëŠö╣Ŕ┐ŤšÜäńŻÖňť░ŃÇé
šşöŠíł 1 :(ňżŚňłć´╝Ü3)
ŠłĹšŤŞń┐튝ëňżłňĄÜŠľ╣Š│ĽňĆ»ń╗ąňüÜňł░Ŕ┐ÖńŞÇšé╣ŃÇéňĆľňć│ń║ÄŠéĘňĆ»ń╗ą/ňŞîŠťŤšöĘŠŁąň«×šÄ░šÜ䚍«ŠáçŃÇé
ŔÁĚšé╣ňżłňĆ»Ŕ⯊ś»šŤŞňÉîšÜä´╝Ü
statsmodels´╝ć´╝â39; linear_model´╝ć´╝â39; .fit()Ŕ┐öňŤ×RegressionResultsš▒╗´╝îňůÂńŞşsummary2()Šľ╣Š│ĽŔ┐öňŤ×ňşÉš▒╗´╝îň╣ÂňŞŽŠťëńŞÇń║ŤŠľ╣ńż┐šÜ䊾╣Š│ĽŃÇé
ňůÂńŞşńŞÇńެńżőňŽé.tablesŔ┐öňŤ×pandas.DataFrameŃÇé
ń╗ąńŞőŠś»ňŽéńŻĽńŻ┐šöĘň«â´╝Ü
import pandas as pd
results = {'Noconst':results_noconstant.summary2(),
'withcon':results_withconstant.summary2()}
df = pd.DataFrame({'Model':[], 'Param':[], 'Value':[]})
for mod in results.keys():
for col in results[mod].tables[0].columns:
if col % 2 == 0:
df = df.append(pd.DataFrame({'Model': [mod]*results[mod].tables[0][col].size,
'Param':results[mod].tables[0][col].values,
'Value':results[mod].tables[0][col+1].values}))
print df
ňô¬ńެŠöšŤŐšÄç´╝Ü
Model Param Value
0 Noconst Model: OLS
1 Noconst Dependent Variable: y
2 Noconst Date: 2016-01-29 00:33
3 Noconst No. Observations: 100
4 Noconst Df Model: 2
5 Noconst Df Residuals: 98
6 Noconst R-squared: 1.000
0 Noconst Adj. R-squared: 1.000
1 Noconst AIC: 296.0102
2 Noconst BIC: 301.2205
3 Noconst Log-Likelihood: -146.01
4 Noconst F-statistic: 9.182e+06
5 Noconst Prob (F-statistic): 4.33e-259
6 Noconst Scale: 1.1079
0 withcon Model: OLS
1 withcon Dependent Variable: y
2 withcon Date: 2016-01-29 00:33
3 withcon No. Observations: 100
4 withcon Df Model: 2
5 withcon Df Residuals: 97
6 withcon R-squared: 1.000
0 withcon Adj. R-squared: 1.000
1 withcon AIC: 297.8065
2 withcon BIC: 305.6220
3 withcon Log-Likelihood: -145.90
4 withcon F-statistic: 4.071e+06
5 withcon Prob (F-statistic): 1.55e-239
6 withcon Scale: 1.1170
ńŻ┐šöĘŠşĄňŐčŔâŻń╗ůÚÖÉń║ÄńŻ┐šöĘpandasšÜäŔâŻňŐŤ - powerful Python data analysis toolkitŃÇé
šşöŠíł 2 :(ňżŚňłć´╝Ü1)
šÄ░ňťĘŠťëńŞÇńެPython versionŠś»ń╝ŚŠëÇňĹĘščąšÜä stargazer RšĘőň║Ćňîů´╝îň«âň░▒Šś»Ŕ┐ÖŠáĚňüÜšÜäŃÇé
ňĆŽŔ»ĚňĆéÚśůń╗ąńŞőšŤŞňů│ÚŚ«Úóś´╝Ühttps://economics.stackexchange.com/q/11774/24531
šşöŠíł 3 :(ňżŚňłć´╝Ü0)
Ŕ┐ÖŠś»ńŞÇńެňĆ»Ŕ⯚Üäň«×šÄ░´╝Ü
import pandas as pd
def compare_statsmodels_ols(estimators, indice=0):
if indice in [0, 2]:
data_dict = {}
if len(estimators) > 1:
for k, est in estimators.iteritems():
data_dict[k] = est.summary2().tables[indice].iloc[:, 1::2].stack().values
index = estimators.popitem()[1].summary2().tables[indice].iloc[:, 0::2].stack().values
df = pd.DataFrame.from_dict(data_dict)
df.index = index
return df
else:
raise 'waiting for a dictionnary for estimators parameter'
else:
raise 'Not working for the coeff table'
estimators = {'m1': m1, 'm2': m2 }
compare_stats_models(estimators, 0)
m1ňĺîm2Šś»ÚóäŔúůŠĘíň×őŃÇé ŠşĄŔžúňć│Šľ╣Šíłń╗ůÚÇéšöĘń║ÄšČČńŞÇńެ´╝łindice = 0´╝ëňĺîšČČńŞëńެ´╝łindice = 2´╝ëolsŠ▒çŠÇ╗ŔíĘŃÇé
Ŕżôňç║´╝Ü
<table border="1" class="dataframe"> <thead> <tr style="text-align: right;"> <th></th> <th>m1</th> <th>m2</th> </tr> </thead> <tbody> <tr> <th>Model:</th> <td>OLS</td> <td>OLS</td> </tr> <tr> <th>Adj. R-squared:</th> <td>0.882</td> <td>0.864</td> </tr> <tr> <th>Dependent Variable:</th> <td>Mpg</td> <td>Mpg</td> </tr> <tr> <th>AIC:</th> <td>254.6367</td> <td>273.3427</td> </tr> <tr> <th>Date:</th> <td>2016-12-14 16:28</td> <td>2016-12-14 16:28</td> </tr> <tr> <th>BIC:</th> <td>389.3848</td> <td>310.7728</td> </tr> <tr> <th>No. Observations:</th> <td>312</td> <td>312</td> </tr> <tr> <th>Log-Likelihood:</th> <td>-91.318</td> <td>-126.67</td> </tr> <tr> <th>Df Model:</th> <td>35</td> <td>9</td> </tr> <tr> <th>F-statistic:</th> <td>67.12</td> <td>220.9</td> </tr> <tr> <th>Df Residuals:</th> <td>276</td> <td>302</td> </tr> <tr> <th>Prob (F-statistic):</th> <td>1.06e-114</td> <td>3.28e-127</td> </tr> <tr> <th>R-squared:</th> <td>0.895</td> <td>0.868</td> </tr> <tr> <th>Scale:</th> <td>0.11885</td> <td>0.13624</td> </tr> </tbody></table>
{kind=link}