жҲ‘жӯЈеңЁзј–еҶҷдёҖдёӘзЁӢеәҸжқҘиҜ„дј°еҜҶз Ғзҡ„ејәеәҰгҖӮжҲ‘зҡ„зЁӢеәҸдёӯзҡ„дёҖдёӘеҮҪж•°жҺҘеҸ—иҫ“е…Ҙзҡ„еҜҶз ҒпјҢ并е°Ҷе…¶дёҺеӨ§йҮҸзҡ„еҚ•иҜҚе’ҢеҜҶз ҒиҝӣиЎҢжҜ”иҫғгҖӮ
иҝҷж®өд»Јз ҒжҳҜдәҢиҝӣеҲ¶жҗңзҙўпјҢеҸҜд»ҘжҹҘзңӢиҫ“е…Ҙзҡ„еҜҶз ҒжҳҜеҗҰеңЁеҜҶз ҒеҲ—иЎЁдёӯгҖӮ
with io.open('PasswordList.txt', encoding='latin-1') as myfile:
data = myfile.readlines()
low = 0
high = (len(data)-1)
while (low <= high) and not Found:
mid = int((low+high)/2)
if data[mid].rstrip() == Password:
Found = True
break
elif Password < str(data[mid]):
high = mid - 1
elif Password > str(data[mid]):
low = mid + 1
иҝҷж®өд»Јз Ғд»ҺеҜҶз ҒдёӯеҲ йҷӨжүҖжңүж•°еӯ—пјҢе°Ҷе…¶еҸҳжҲҗжҷ®йҖҡеӯ—жҜҚ并еҶҚж¬ЎеҜ№з…§еҲ—иЎЁиҝӣиЎҢжЈҖжҹҘгҖӮ пјҶпјғ34; Password123пјҶпјғ34;дјҡеҸҳжҲҗпјҶпјғ34;еҜҶз ҒпјҶпјғ34;е’ҢпјҶпјғ34;еҜҶз ҒпјҶпјғ34;еңЁеҲ—иЎЁдёӯгҖӮ
SimplePassword = ''.join([i for i in Password if not i.isdigit()])
SimplePassword = SimplePassword.lower()
if not Found:
with io.open('final.txt', encoding='latin-1') as myfile:
data = myfile.readlines()
low = 0
high = (len(data)-1)
while (low <= high) and not Found:
mid = int((low+high)/2)
if data[mid].rstrip() == SimplePassword:
PartiallyFound = True
break
elif SimplePassword < str(data[mid]):
high = mid - 1
elif SimplePassword > str(data[mid]):
low = mid + 1
жҲ‘жғійҖҡиҝҮзј–еҶҷдёҖдәӣеҸҜд»ҘиҜҶеҲ«еӯ—з¬ҰдёІдёӯзҡ„еҗҚз§°жҲ–еҚ•иҜҚзҡ„д»Јз ҒжқҘиҝӣдёҖжӯҘиҖғиҷ‘иҝҷдёҖзӮ№гҖӮдҫӢеҰӮпјҢпјҶпјғ34; johnпјҶпјғ34;еңЁеҲ—иЎЁе’ҢеҚ•иҜҚпјҶпјғ34; smithпјҶпјғ39;еңЁеҲ—иЎЁдёӯгҖӮдҪҶжҳҜпјҢиҫ“е…Ҙзҡ„еҜҶз ҒпјҶпјғ34; JohnSmith123пјҶпјғ34;дјҡеңЁйӣ·иҫҫдёӢйЈһиЎҢгҖӮ
жҲ‘жҖҺж ·жүҚиғҪе°Ҷе®ғеҲҶжҲҗеҚ•зӢ¬зҡ„еҚ•иҜҚпјҹжҲ‘жӯЈеңЁиҖғиҷ‘зҡ„дёҖз§Қж–№жі•жҳҜе°ҶеӨ§еҶҷеӯ—жҜҚд№Ӣй—ҙзҡ„еӯ—жҜҚйҷ„еҠ еҲ°ж•°з»„дёӯпјҢ然еҗҺеҚ•зӢ¬жЈҖжҹҘиҜҘж•°з»„дёӯзҡ„жҜҸдёӘе…ғзҙ гҖӮ
дҪҶеҝ…йЎ»жңүжӣҙеҘҪзҡ„ж–№жі•гҖӮжҳҜеҗҰжңүжҹҗз§Қж–№жі•еҸҜд»ҘжҹҘзңӢиҫ“е…Ҙзҡ„еҜҶз ҒжҳҜеҗҰеҸҜд»Ҙж №жҚ®еӨ§еһӢиҜҚжұҮиЎЁдёӯзҡ„еҚ•иҜҚеҸҳдҪ“жһ„е»әпјҹ
зӯ”жЎҲ 0 :(еҫ—еҲҶпјҡ2)
дҪ еҸҜд»ҘиҜ•иҜ•
badness = 0
for word in wordlist:
if word in passwordString and len(word) > badness:
badness = len(word)
иҝҷж ·пјҢеҜҶз ҒиҝҷдёӘиҜҚе°ұдјҡеҸ—еҲ°пјҡ
дҪҶе®һйҷ…дёҠеҸӘдјҡдҪҝз”ЁвҖңеҜҶз ҒвҖқгҖӮ
зӯ”жЎҲ 1 :(еҫ—еҲҶпјҡ1)
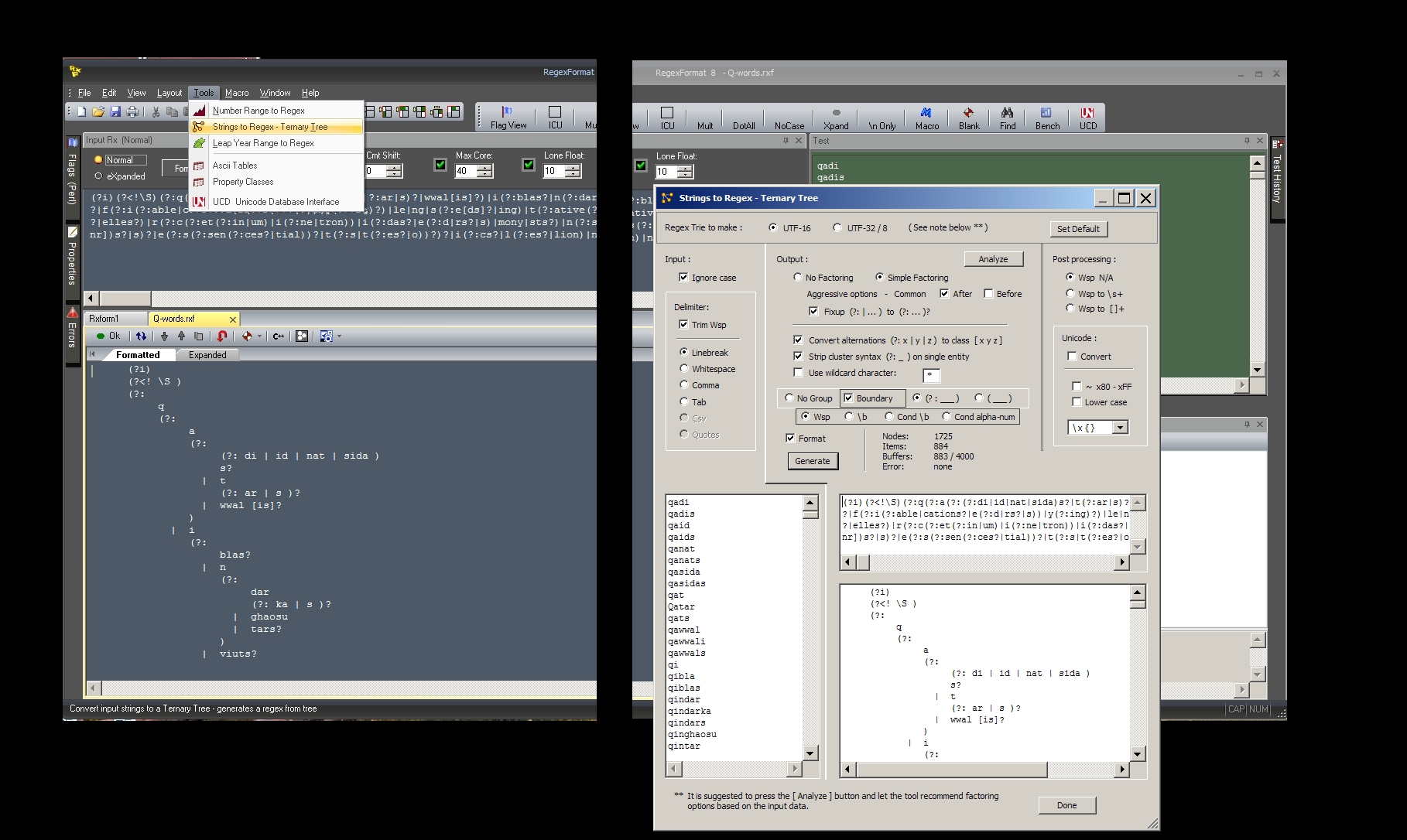
from variations of words inside a large wordlist
There is a tool you can use to construct a regex Trie from your
word list.
You just paste in all the variations into a text box, and it pumps out
a full blown regex trie.
This is probably the fastest lookup there is.
The tool is available in the trial version.
Screen shot Tool.
App runs on Windows only.
Location from main menu is Tools->Ternary Tree
Benchmark
Regex1:
Completed iterations: 1 / 1 ( x 1000 )
Matches found per iteration: 174939
Elapsed Time: 600.30 s, 600296.36 ms, 600296365 Вөs
Target Sample: All 174,939 words that the regex represents (in random order)
Sample Analysis:
174,939 words matched / iteration
x 1,000 iterations
------------------------------
174,939,000 total words matched
/ 600 total seconds
------------------------------
291,565 words matched / second <<<
/ 1,000 miliseconds / second
------------------------------
292 words matched / milisecond <<<
{kind=link}