什么是hadoop(单个和多个)节点,spark-master和spark-worker?
我想了解以下条款:
hadoop(单节点和多节点) 火花大师 火花工人 名称节点 数据节点
到目前为止我所理解的是,火花大师是工作执行者并处理所有火花工人。而hadoop是hdfs(我们的数据所在的位置),而spark工作者则根据给予他们的工作读取数据。如果我错了,请纠正我。
我还想了解namenode和datanode的作用。虽然我知道namenode的作用(拥有所有datanode的元数据信息,但它应该只有一个(优先)但可能是两个)并且datanode可能是多个并且拥有数据。
datanode是否与hadoop节点相同?
请照亮我。
提前致谢。
2 个答案:
答案 0 :(得分:4)
SPARK架构:
Spark使用master/worker architecture。有一个驱动程序与一个名为master的协调器进行通信,该协调器管理执行程序运行的工作程序。

驱动程序和执行程序在它们自己的Java进程中运行。您可以在相同(水平集群)或单独的计算机(垂直集群)上或在混合计算机配置中运行它们。
节点只不过是物理机器。
Hadoop NameNode和DataNode:
HDFS具有主/从架构。 HDFS集群由单个NameNode,一个管理文件系统命名空间的主服务器和管理客户端对文件的访问组成。此外,还有许多DataNode,通常是群集中每个节点一个,用于管理连接到它们运行的节点的存储。 HDFS公开文件系统命名空间,并允许用户数据存储在文件中。在内部,文件被分成一个或多个块,这些块存储在一组DataNode中。 NameNode执行文件系统命名空间操作,如打开,关闭和重命名文件和目录。它还确定了块到DataNode的映射。 DataNode负责提供来自文件系统客户端的读写请求。 DataNode还根据NameNode的指令执行块创建,删除和复制。
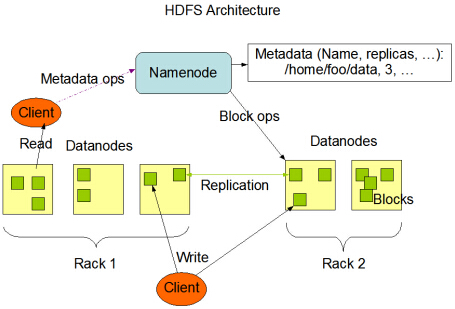
是的,DataNodes是Hadoop集群中的从属节点。
请参阅文档以获取更多详细信息。
答案 1 :(得分:0)
Hadoop单节点具有1个Namenode(主节点)和1个Datanode(从节点)的Hadoop集群。 Namenode具有所有元数据,并将其分配给存储数据并完成处理的从属数据节点。
Hadoop多节点具有1个Namenode(主节点)和n个Datanode(从节点)的Hadoop集群
火花大师与HDFS中的Namenode相同
spark worker 与datanode相同,但是spark worker仅用于处理不存储数据的情况。
将事物置于上下文中(简单)-如果有1个Namenode和2个datanode(1GB内存)集群。 2 GB的文件将被拆分并存储在datanodes上。类似于spark作业,将被拆分以并行处理各个数据节点(工人)上的数据。
- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?