如何将文本与正则表达式匹配,忽略标点符号和换行符
我有一个应用程序,我需要在文本段落中找到单词列表的位置。一个正则表达式显然是这样做的方式,但我的问题是我可能有各种标点符号或单词之间的新行。我怎么做"发现这些单词可能是分开的但是有一些非字母数字字符"?
更新:
一个例子是我需要找到以下范围:
  大声帮助这些正则表达式很可怕所以
Âú®
  开发人员大声喊叫"帮助",这些正则表达式太可怕了!   所以,请帮助我:(
2 个答案:
答案 0 :(得分:-1)
描述
\b(?:[a-z](?:[a-z\n\r.:;,?!-]*[a-z])?)\b

**点击查看大图
此正则表达式将执行以下操作:
- 要求所有字词以
a-z开头和结尾,或者长一个字母 - 允许字词包含换行符或
.:;,?!-等常见标点符号
- 不允许包含空格
实施例
现场演示
https://regex101.com/r/bK4oO8/1
示例文字
How do I match text with a regular expres
sion ignoring punctuation and line breaks?
How do I do "find these words pos-
sibly separated but some non-alphanumeric characters"?
样本匹配
MATCH 1
0. [0-3] `How`
MATCH 2
0. [4-6] `do`
MATCH 3
0. [7-8] `I`
MATCH 4
0. [9-14] `match`
MATCH 5
0. [15-19] `text`
MATCH 6
0. [20-24] `with`
MATCH 7
0. [25-26] `a`
MATCH 8
0. [27-34] `regular`
MATCH 9
0. [35-46] `expres
sion`
MATCH 10
0. [47-55] `ignoring`
MATCH 11
0. [56-67] `punctuation`
MATCH 12
0. [68-71] `and`
MATCH 13
0. [72-76] `line`
MATCH 14
0. [77-88] `breaks?
How`
MATCH 15
0. [89-91] `do`
MATCH 16
0. [92-93] `I`
MATCH 17
0. [94-96] `do`
MATCH 18
0. [98-102] `find`
MATCH 19
0. [103-108] `these`
MATCH 20
0. [109-114] `words`
MATCH 21
0. [115-125] `pos-
sibly`
MATCH 22
0. [126-135] `separated`
MATCH 23
0. [136-139] `but`
MATCH 24
0. [140-144] `some`
MATCH 25
0. [145-161] `non-alphanumeric`
MATCH 26
0. [162-172] `characters`
解释
NODE EXPLANATION
----------------------------------------------------------------------
\b the boundary between a word char (\w) and
something that is not a word char
----------------------------------------------------------------------
(?: group, but do not capture:
----------------------------------------------------------------------
[a-z] any character of: 'a' to 'z'
----------------------------------------------------------------------
(?: group, but do not capture (optional
(matching the most amount possible)):
----------------------------------------------------------------------
[a-z\n\r.:;,?!- any character of: 'a' to 'z', '\n'
]* (newline), '\r' (carriage return),
'.', ':', ';', ',', '?', '!', '-' (0
or more times (matching the most
amount possible))
----------------------------------------------------------------------
[a-z] any character of: 'a' to 'z'
----------------------------------------------------------------------
)? end of grouping
----------------------------------------------------------------------
) end of grouping
----------------------------------------------------------------------
\b the boundary between a word char (\w) and
something that is not a word char
----------------------------------------------------------------------
额外信用
如果您还想删除上面#14之类的匹配项,那么您的?后跟一个换行符。在此配置中,?不应被视为单词的一部分,其中后跟新行的-实际上是连字符。那你应该考虑这个
\b(?:[a-z](?:(?:[a-z-]+|[.:;,?!-]+(?![\n\r])|[\n\r]+)*[a-z])?)\b
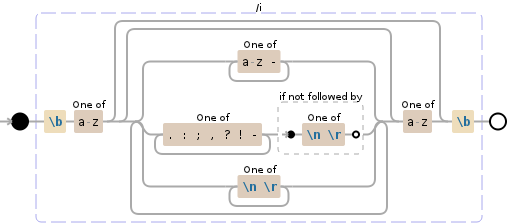
现场演示:https://regex101.com/r/bK4oO8/2
答案 1 :(得分:-1)
我明白了:
let pattern = String(format: "(\\b%@\\b)",words.joinWithSeparator("[^a-zA-Z\\d\\s:]?[ ]"))
'\ b'给出单词边界然后它匹配分隔的单词,但是可选的标点字符然后是空格。我可能需要为双标点添加一些位,但现在可以使用。
- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?