我在java中有一个很长的字符串,我正在尝试获取该字符串的统计信息。
例如String s =“afafaf”
我希望获得长度为2的所有现有子串的所有计数。 对于上面的这个小例子,这将是:
“af” - 3 “fa” - 2
另一个例子: String s =“hsdjs”
结果: “hs” - 1 “sd” - 1 “dj” - 1 “js” - 1
我所做的和正在做的是用for(int i = 0; i< s.length; i ++)和迭代Map条目来查找字符串。
问题是该死的慢。 我想也许用于并行处理的新Java8函数可能对我有帮助。但不幸的是,我无法运行......也许有人可以帮助我。
当前代码:
import com.google.common.collect.HashMultiset;
String inputString = s;
HashMultiset<String> multi = HashMultiset.create();
for (int i=0;i <inputString.length()-1;i++) {
String aktuellerString = inputString.substring(i, i+2);
multi.add(aktuellerString);
}
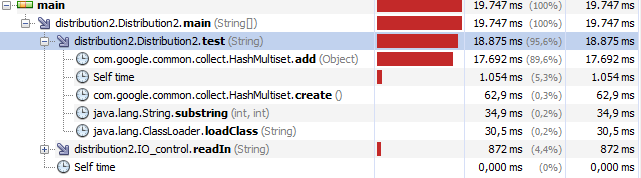
以下是当前的分析: http://fs5.directupload.net/images/160909/naadsfxi.png
google guava库的HashMultiset的add()方法实际上花费了大部分时间。但这是我能找到的最快的收藏品。 (尝试了几个其他优化的库,包括普通的HashMap,Tie,GS Collections,gnu.trove.map.hash.THashMap; import org.apache.commons.collections.FastHashMap,...)。
这就是为什么我认为并行处理可能是加速的唯一方法。
答案 0 :(得分:3)
更新:正如Marko指出的那样,创建子字符串的成本很高,即使有多个CPU,你也可以通过一个避免创建它们的结构来做得更好。在这种情况下,我们只有两个字符,这些字符可以编码为int值。在这种情况下,我们可以假设ASCII字符。
public static void main(String[] args) throws IOException {
char[] chars = new char[1000000000];
Random rand = new Random();
for (int i = 0; i < chars.length; i++)
chars[i] = (char) (rand.nextInt(26) + 'a');
String s = new String(chars);
long start = System.currentTimeMillis();
Map<String, Integer> freq = IntStream.range(0, s.length() - 1).parallel()
.mapToObj(i -> s.substring(i, i + 2))
.collect(Collectors.groupingBy(w -> w, Collectors.summingInt(e -> 1)));
long time = System.currentTimeMillis() - start;
System.out.println("Took " + time + " ms " + freq);
}
打印
Took 8401 ms {aa=1479201, ab=1478451, ac=1479055, ...
但是,如果我们直接使用collect,我们可以使用不会创建任何对象的结构。
public static void main(String[] args) throws IOException {
char[] chars = new char[1000000000];
Random rand = new Random();
for (int i = 0; i < chars.length; i++)
chars[i] = (char) (rand.nextInt(26) + 'a');
String s = new String(chars);
long start = System.currentTimeMillis();
int[] freqArr = IntStream.range(0, s.length() - 1).parallel()
.collect(() -> new int[128 * 128],
(arr, i) -> arr[s.charAt(i) * 128 + s.charAt(i + 1)]++,
(a, b) -> sum(a, b));
Map<String, Integer> freq = new TreeMap<>();
for (int i = 0; i < freqArr.length; i++) {
int c = freqArr[i];
if (c == 0) continue;
String key = "" + (char) (i >> 7) + (char) (i & 0x7f);
freq.put(key, c);
}
long time = System.currentTimeMillis() - start;
System.out.println("Took " + time + " ms " + freq);
}
static int[] sum(int[] a, int[] b) {
for (int i = 0; i < a.length; i++)
a[i] += b[i];
return a;
}
打印以下内容,速度提高约20倍。
Took 404 ms {aa=1479575, ab=1480511, ac=1476255,
这有很大的不同,因为我们正在处理小字符串
您可以替换
for (int i=0; i < s.length;i++) { something(i) }
与
IntStream.range(0, s.length()).parallel().forEach(i -> { something(i) })
但更好的解决方案是使用映射......
String s = "afafaffafafafffafaaaf";
Map<String, Long> freq = IntStream.range(0, s.length()-1).parallel() // 1
.mapToObj(i -> s.substring(i, i + 2)) // 2
.collect(Collectors.groupingBy(w -> w, Collectors.counting())); //3
System.out.println(freq);
打印
{ff=3, aa=2, af=8, fa=7}
关于霍尔格关于分组可能更慢的观点,我测试了四个案例。
long start = System.currentTimeMillis();
Map<Integer, Long> freq = IntStream.range(0,1000000000)/*.parralel()*/
.mapToObj(i -> i % 10)
.collect(Collectors.groupingBy/*Concurrent*/(w -> w, Collectors.counting()));
long time = System.currentTimeMillis() - start;
System.out.println("Took " + time+" ms " + freq);
without parallel(), with groupingBy : Took 14156 ms {0=100000000, 1=100000000, 2=100000000, 3=100000000, 4=100000000, 5=100000000, 6=100000000, 7=100000000, 8=100000000, 9=100000000}
with parallel(), with groupingBy : Took 5581 ms {0=100000000, 1=100000000, 2=100000000, 3=100000000, 4=100000000, 5=100000000, 6=100000000, 7=100000000, 8=100000000, 9=100000000}
without parallel(), with groupingByConcurrent : Took 38218 ms {0=100000000, 1=100000000, 2=100000000, 3=100000000, 4=100000000, 5=100000000, 6=100000000, 7=100000000, 8=100000000, 9=100000000}
with parallel(), with groupingByConcurrent : Took 27619 ms {0=100000000, 1=100000000, 2=100000000, 3=100000000, 4=100000000, 5=100000000, 6=100000000, 7=100000000, 8=100000000, 9=100000000}
使用groupingBy是最好的解决方案,无论是否并行。
进一步使用Holger的评论,通过使用summingInt,这再次被证明更快。
long start = System.currentTimeMillis();
Map<Integer, Integer> freq = IntStream.range(0, 1000000000).parallel()
.mapToObj(i -> i % 10)
.collect(Collectors.groupingBy(w -> w, Collectors.summingInt(e -> 1)));
long time = System.currentTimeMillis() - start;
System.out.println("Took " + time+" ms " + freq);
打印
Took 4131 ms {0=100000000, 1=100000000, 2=100000000, 3=100000000, 4=100000000, 5=100000000, 6=100000000, 7=100000000, 8=100000000, 9=100000000}
{kind=link}