什么卷积操作用于图像识别?
我在特征识别中发现卷积的所有人为例子都简化了#34;通过使像素值为1或-1来进行卷积运算。它实现了一个非常简单的操作(按滤波器像素乘以输入像素,求和结果,然后除以像素数):
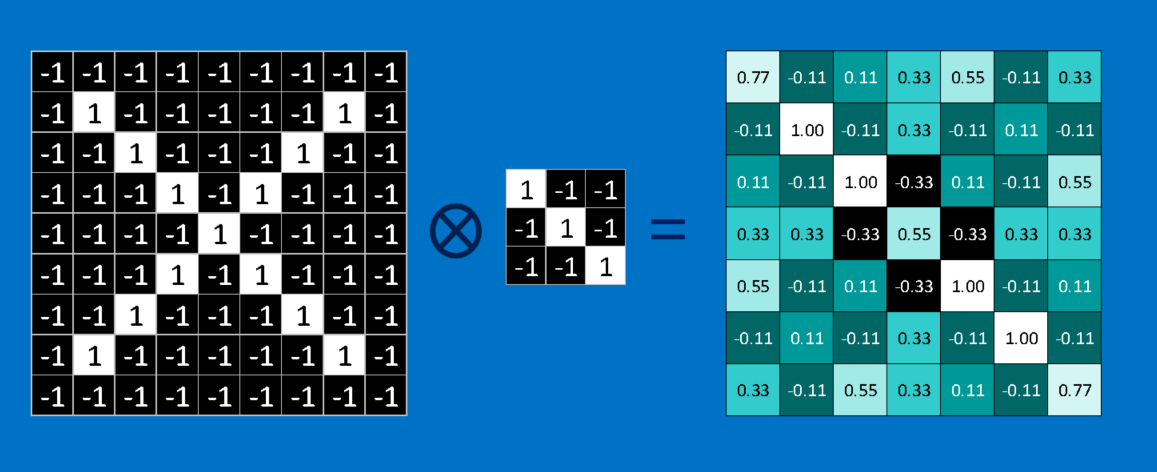
但是,对于像素值具有范围的大多数图像,它并没有什么帮助。例如。 (0.0-1.0),或(0-255)。
我无法找到用于这些输入值的算法的示例。我尝试对每个像素的差异进行求和,然后除以像素数以获得整体"错误"。然后激活等于max - error。例如。 255 - 错误,或1.0 - 错误。
它永远不会输出负值,所以我不认为需要ReLU层。这让我觉得这是一种天真的做法,并不会真正起作用,但我不确定为什么。
那么当输入数据不是1 / -1时使用的操作是什么?
编辑以下是我一直关注的示例:http://brohrer.github.io/how_convolutional_neural_networks_work.html
它描述的卷积操作:
要计算要素与图像块的匹配,只需将要素中的每个像素乘以图像中相应像素的值即可。然后将答案加起来并除以要素中的总像素数。如果两个像素都是白色(值为1)则1 * 1 = 1.如果两者都是黑色,则(-1)*( - 1)= 1.无论哪种方式,每个匹配的像素都会产生1.同样,任何不匹配是-1。
一个具体的例子,说明为什么我不认为这适用于值为[0.0,1.0]的像素。假设我们有1x1过滤器,其值为[0.5]。如果我们在值为0.5的输入像素上运行,那么我们得到0.25。
同样,如果我们使用[0,255]的颜色范围,那么我们很容易得到值> 255.虽然我不确定这是否重要,因为它不再是像素数据;它在功能图中的激活,对吧?
2 个答案:
答案 0 :(得分:1)
通常,您对每个像素使用卷积。因此,每个像素都是具有所有这些权重的所有像素的总和。因此,角落像素为0.77 *,其他角落为0.33 *,所有这些值都加起来并放入中心。通常是卷曲的。然后对所有其他像素进行相同的操作而不重叠任何数据。
该像素的下一个版本的值是几个像素的总和。有时,这是通过权重给出的。因此,不是乘以-1,而是乘以每个像素的权重。
您通常会对卷积权重进行标准化。在这种情况下,9.44444444444444444并将各种权重的各种像素的总和除以该量。但是,这显然是Canny边缘检测,这意味着要点超出给定范围并仅划分边缘。这意味着取决于内核,它可能允许最高范围为9.44倍。并且底值范围为负值。然后你压缩例程并将给定的像素截断到0-255或0.0-1.0的范围内(取决于你使用的是什么)。这会丢失很多数据,但这就是重点,它希望失去噪音并保持边缘。
答案 1 :(得分:0)
通常,您需要将输入阈值作为第一遍转换为二进制。当然,您可以对灰度图像进行卷积,而Canny线检测就是这样做的。但结果是另一个连续的图像,需要进一步处理。
我的github项目中有一些关于二进制图像处理的资料,这里 http://malcolmmclean.github.io/binaryimagelibrary/
- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?