PDFBoxеңЁе…ӢйҡҶйЎөйқўж—¶зңҒз•ҘиЎЁеҚ•еӯ—ж®ө
жҲ‘е°қиҜ•дҪҝз”ЁPDFBoxе’ҢGroovyеҲӣе»әеӨҡйЎөж–ҮжЎЈгҖӮ жҲ‘жңүдёҖдёӘжЁЎжқҝж–ҮжЎЈпјҢе…¶дёӯеҢ…еҗ«дёҖдәӣиЎЁеҚ•ж–Үжң¬еӯ—ж®өпјҢжҜҸж¬ЎеҲӣе»әж–°ж–ҮжЎЈж—¶пјҢзЁӢеәҸйғҪдјҡдҪҝз”ЁжӯӨжЁЎжқҝгҖӮ
жҲ‘зҡ„й—®йўҳжҳҜпјҢжҜҸеҪ“жҲ‘е°қиҜ•еҲӣе»әж–°ж–ҮжЎЈж—¶пјҢж–°ж–ҮжЎЈдёӯзҡ„жҹҗдәӣиЎЁеҚ•еӯ—ж®өйғҪдјҡдёўеӨұгҖӮжҲ‘е’ҢFoxit PhantomPDFеҗҲдҪңпјҢеңЁи§Ҷи§үдёҠпјҢжҲ‘зңӢдёҚеҲ°дёўеӨұзҡ„еӯ—ж®өгҖӮжҲ‘зңӢеҲ°зҡ„е…¶д»–дәәйғҪеҫҲеҘҪгҖӮ
иҝҷжҳҜжҲ‘зҡ„д»Јз Ғпјҡ
static void initiatePdf() {
// Initiate a new PDF Box object and get the acro form from it
File file = new File(Constants.EMPTY_DOC)
PDDocument tempDoc
Evaluator evaluator = new Evaluator()
int numPages = evaluator.getNumOfPagesRequired(objects)
for(int i = 0; i < numPages; i++) {
tempDoc = new PDDocument().load(file)
PDDocumentCatalog docCatalog = tempDoc.getDocumentCatalog()
PDAcroForm acroForm = docCatalog.acroForm
PDPage page = (PDPage) docCatalog.getPages().get(0)
document.addPage(page)
}
document.save(Constants.RESULT_FILE)
document.close()
}
иҝҷжҳҜдёҖеј жңүеҠ©дәҺжҸҸз»ҳжҲ‘зҡ„й—®йўҳзҡ„еӣҫзүҮгҖӮиҝҷжҳҜжЁЎжқҝпјҡ
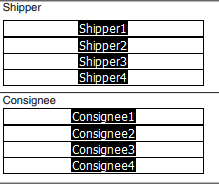
иҝҷжҳҜж–°зҡ„pdfж–Ү件
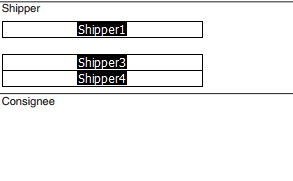
1 дёӘзӯ”жЎҲ:
зӯ”жЎҲ 0 :(еҫ—еҲҶпјҡ0)
жҲ‘и®ҫжі•еңЁTilman Hausherrзҡ„её®еҠ©дёӢи§ЈеҶідәҶиҝҷдёӘй—®йўҳгҖӮиҝҷжҳҜдҪҚдәҺforеҫӘзҺҜд№ӢеҗҺзҡ„д»Јз ҒгҖӮ
PDAcroForm acroForm = new PDAcroForm(document, acroFormDict);
acroForm.setFields(fields)
acroForm.setDefaultResources(res);
PDDocumentCatalog catalog = document.getDocumentCatalog();
catalog.setAcroForm(acroForm);
зӣёе…ій—®йўҳ
жңҖж–°й—®йўҳ
- жҲ‘еҶҷдәҶиҝҷж®өд»Јз ҒпјҢдҪҶжҲ‘ж— жі•зҗҶи§ЈжҲ‘зҡ„й”ҷиҜҜ
- жҲ‘ж— жі•д»ҺдёҖдёӘд»Јз Ғе®һдҫӢзҡ„еҲ—иЎЁдёӯеҲ йҷӨ None еҖјпјҢдҪҶжҲ‘еҸҜд»ҘеңЁеҸҰдёҖдёӘе®һдҫӢдёӯгҖӮдёәд»Җд№Ҳе®ғйҖӮз”ЁдәҺдёҖдёӘз»ҶеҲҶеёӮеңәиҖҢдёҚйҖӮз”ЁдәҺеҸҰдёҖдёӘз»ҶеҲҶеёӮеңәпјҹ
- жҳҜеҗҰжңүеҸҜиғҪдҪҝ loadstring дёҚеҸҜиғҪзӯүдәҺжү“еҚ°пјҹеҚўйҳҝ
- javaдёӯзҡ„random.expovariate()
- Appscript йҖҡиҝҮдјҡи®®еңЁ Google ж—ҘеҺҶдёӯеҸ‘йҖҒз”өеӯҗйӮ®д»¶е’ҢеҲӣе»әжҙ»еҠЁ
- дёәд»Җд№ҲжҲ‘зҡ„ Onclick з®ӯеӨҙеҠҹиғҪеңЁ React дёӯдёҚиө·дҪңз”Ёпјҹ
- еңЁжӯӨд»Јз ҒдёӯжҳҜеҗҰжңүдҪҝз”ЁвҖңthisвҖқзҡ„жӣҝд»Јж–№жі•пјҹ
- еңЁ SQL Server е’Ң PostgreSQL дёҠжҹҘиҜўпјҢжҲ‘еҰӮдҪ•д»Һ第дёҖдёӘиЎЁиҺ·еҫ—第дәҢдёӘиЎЁзҡ„еҸҜи§ҶеҢ–
- жҜҸеҚғдёӘж•°еӯ—еҫ—еҲ°
- жӣҙж–°дәҶеҹҺеёӮиҫ№з•Ң KML ж–Ү件зҡ„жқҘжәҗпјҹ