有人可以解释这句话:
shared variables
x = 0, y = 0
Core 1 Core 2
x = 1; y = 1;
r1 = y; r2 = x;
如何在x86处理器上拥有r1 == 0和r2 == 0?
答案 0 :(得分:27)
由于涉及reordering of instructions的优化,可能会出现问题。换句话说,两个处理器可以在分配变量r1和r2之前分配x和y ,如果他们发现这会产生更好的性能。这可以通过添加memory barrier来解决,这将强制执行排序约束。
引用帖子中提到的slideshow:
现代多核/语言打破顺序一致性。
关于x86架构,最佳资源是Intel® 64 and IA-32 Architectures Software Developer’s Manual(章节 8.2内存排序)。 8.2.1和8.2.2节描述了由...实现的内存排序 Intel486,Pentium,Intel Core 2 Duo,Intel Atom,Intel Core Duo,Pentium 4,Intel Xeon和P6系列处理器:一种称为处理器订购的内存模型,而不是旧版Intel386架构的程序订购(强大订购)(其中读写指令总是按它们出现在指令流中的顺序发出。
本手册描述了处理器订购内存模型的许多订购保证(例如负载未与其他负载重新排序,商店未与其他商店重新订购,商店不会使用较旧的负载重新排序等),但它还描述了允许的重新排序规则,该规则会导致OP帖子中的竞争条件:
8.2.3.4负载可能会与较早的商店重新排序 地点
另一方面,如果切换了指令的原始顺序:
shared variables
x = 0, y = 0
Core 1 Core 2
r1 = y; r2 = x;
x = 1; y = 1;
在这种情况下,处理器保证不允许r1 = 1和r2 = 1情况(由于 8.2.3.3商店没有按早期加载重新排序保证),这意味着这些指令永远不会在单个核心中重新排序。
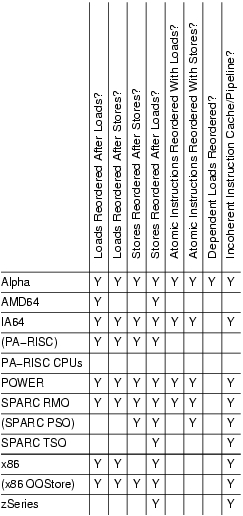
要将其与不同的体系结构进行比较,请查看以下文章:Memory Ordering in Modern Microprocessors(具体为this image)。您可以看到Itanium(IA-64)比IA-32架构更加重新排序。
答案 1 :(得分:3)
在具有较弱内存一致性模型的处理器(例如SPARC,PowerPC,Itanium,ARM等)上,由于在没有显式内存屏障指令的情况下写入时缺乏强制缓存一致性,因此可能发生上述情况。因此Core1基本上x会在y之前看到Core2上的写入,而y会在x之前看到volatile上的写入。在这种情况下,不需要完整的fence指令...基本上你只需要在这种情况下强制执行写或释放语义,以便所有写入都被提交并且对所有处理器可见,然后才对这些变量进行读取写给。具有强大的内存一致性模型(如x86)的处理器体系结构通常会使这变得不必要,但正如Groo所指出的,编译器本身可以重新排序操作。您可以在C和C ++中使用volatile关键字来防止编译器在给定线程内重新排序操作。这并不是说volatile将创建线程安全的代码来管理线程之间的读写可见性......需要一个内存屏障。因此,虽然使用{{1}}仍然可以创建不安全的线程代码,但在给定的线程中,它将在编译的机器代码级别强制执行顺序一致性。
答案 2 :(得分:2)
问题是两个语句都没有强制执行它们的两个语句之间的任何顺序,因为它们不是相互依赖的。
编译器知道 x 和 y 没有别名,因此不需要订购操作。
CPU知道 x 和 y 没有别名,因此可能会对它们进行重新排序以提高速度。发生这种情况的一个很好的例子是当CPU检测到write combining的机会时。如果它可以这样做而不违反其一致性模型,它可以将一个写入与另一个写入合并。
相互依赖看起来很奇怪,但它与任何其他种族条件没有什么不同。直接编写共享内存线程代码非常困难,这就是开发并行语言和消息传递并行框架的原因,以便将并行危险隔离到一个小内核并消除应用程序本身的危害。
{kind=link}