жҺ’еәҸеҲ—иЎЁе·®ејӮ
жҲ‘жңүд»ҘдёӢй—®йўҳгҖӮ
жҲ‘жңүдёҖз»„е…ғзҙ пјҢжҲ‘еҸҜд»ҘжҢүжҹҗз§Қз®—жі•AжҺ’еәҸгҖӮеҲҶжӢЈеҫҲеҘҪпјҢдҪҶйқһеёёжҳӮиҙөгҖӮ
иҝҳжңүдёҖдёӘз®—жі•BеҸҜд»Ҙиҝ‘дјјAзҡ„з»“жһңгҖӮе®ғжӣҙеҝ«пјҢдҪҶжҺ’еәҸдёҚдјҡе®Ңе…ЁзӣёеҗҢгҖӮ
е°ҶAзҡ„иҫ“еҮәдҪңдёәвҖңй»„йҮ‘ж ҮеҮҶвҖқпјҢжҲ‘йңҖиҰҒеҜ№еңЁзӣёеҗҢж•°жҚ®дёҠдҪҝз”ЁBзҡ„й”ҷиҜҜиҝӣиЎҢжңүж„Ҹд№үзҡ„дј°и®ЎгҖӮ
д»»дҪ•дәәйғҪеҸҜд»Ҙе»әи®®жҲ‘еҸҜд»ҘжҹҘзңӢд»»дҪ•иө„жәҗжқҘи§ЈеҶіжҲ‘зҡ„й—®йўҳеҗ—пјҹ жҸҗеүҚи°ўи°ўпјҒ
зј–иҫ‘пјҡ
ж №жҚ®иҰҒжұӮпјҡж·»еҠ дёҖдёӘдҫӢеӯҗжқҘиҜҙжҳҺжЎҲдҫӢпјҡ еҰӮжһңж•°жҚ®жҳҜеӯ—жҜҚиЎЁзҡ„еүҚ10дёӘеӯ—жҜҚпјҢ
Aиҫ“еҮәпјҡaпјҢbпјҢcпјҢdпјҢeпјҢfпјҢgпјҢhпјҢiпјҢj
Bиҫ“еҮәпјҡaпјҢbпјҢdпјҢcпјҢeпјҢgпјҢhпјҢfпјҢjпјҢi
дә§з”ҹй”ҷиҜҜзҡ„еҸҜиғҪжҺӘж–ҪжҳҜд»Җд№ҲпјҢиҝҷж ·жҲ‘е°ұеҸҜд»Ҙи°ғж•ҙз®—жі•Bзҡ„еҶ…йғЁеҸӮж•°пјҢдҪҝз»“жһңжӣҙжҺҘиҝ‘Aзҡ„иҫ“еҮәпјҹ
6 дёӘзӯ”жЎҲ:
зӯ”жЎҲ 0 :(еҫ—еҲҶпјҡ4)
жҲ‘дјҡзЎ®е®ҡжңҖеӨ§зҡ„жӯЈзЎ®жҺ’еәҸеӯҗйӣҶгҖӮ
+-------------> I
| +--------->
| |
A -> B -> D -----> E -> G -> H --|--> J
| ^ | | ^
| | | | |
+------> C ---+ +-----------> F ---+
еңЁдҪ зҡ„дҫӢеӯҗдёӯпјҢ7дёӘдёӯжңү7дёӘпјҢжүҖд»Ҙз®—жі•еҫ—еҲҶдёә0.7гҖӮе…¶д»–з»„зҡ„й•ҝеәҰдёә6.жӯЈзЎ®зҡ„жҺ’еәҸеҲҶж•°дёә1.0пјҢеҸҚеҗ‘жҺ’еәҸдёә1 / nгҖӮ
жҲ‘и®ӨдёәиҝҷдёҺеҸҚиҪ¬ж¬Ўж•°жңүе…ігҖӮ x + yиЎЁзӨәx <= yпјҲжӯЈзЎ®йЎәеәҸпјүпјҢx-yиЎЁзӨәx> yгҖӮ yпјҲй”ҷиҜҜзҡ„и®ўеҚ•пјүгҖӮ
A + B + D - C + E + G + H - F + J - I
жҲ‘们иҺ·еҫ—дәҶеҮ д№ҺзӣёеҗҢзҡ„з»“жһң - 9дёӘдёӯзҡ„6дёӘжҳҜжӯЈзЎ®зҡ„sc 0.667гҖӮеҶҚж¬ЎжӯЈзЎ®зҡ„жҺ’еәҸеҲҶж•°1.0е’ҢеҸҚеҗ‘жҺ’еәҸ0.0пјҢиҝҷеҸҜиғҪжӣҙе®№жҳ“и®Ўз®—гҖӮ
зӯ”жЎҲ 1 :(еҫ—еҲҶпјҡ4)
ж–Ҝзҡ®е°”жӣјзҡ„rho
жҲ‘и®ӨдёәдҪ жғіиҰҒзҡ„жҳҜSpearman's rank correlation coefficientгҖӮдҪҝз”ЁдёӨдёӘжҺ’еәҸзҡ„зҙўеј•[rank]еҗ‘йҮҸпјҲе®ҢзҫҺAе’Ңиҝ‘дјјBпјүпјҢжӮЁеҸҜд»Ҙи®Ўз®—д»Һ-1пјҲе®Ңе…ЁдёҚеҗҢпјүеҲ°1пјҲе®Ңе…ЁдёҚеҗҢпјүзҡ„зӯүзә§зӣёе…іrhoзӣёеҗҢпјүпјҡ
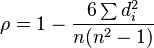
е…¶дёӯdпјҲiпјүжҳҜAе’ҢBд№Ӣй—ҙжҜҸдёӘеӯ—з¬Ұзҡ„зӯүзә§е·®ејӮ
жӮЁеҸҜд»Ҙе°ҶиҜҜе·®иЎЎйҮҸж ҮеҮҶе®ҡд№үдёәи·қзҰ»D := (1-rho)/2гҖӮ
зӯ”жЎҲ 2 :(еҫ—еҲҶпјҡ3)
жӮЁжҳҜеҗҰжӯЈеңЁеҜ»жүҫдёҖдәӣеҹәдәҺдҪҝз”ЁAжҺ’еәҸзҡ„ж•°з»„е’Ңд»ҘBдҪңдёәиҫ“е…ҘжҺ’еәҸзҡ„ж•°з»„жқҘи®Ўз®—е·®ејӮзҡ„з®—жі•пјҹжҲ–иҖ…жӮЁжҳҜеҗҰжӯЈеңЁеҜ»жүҫдёҖз§ҚйҖҡз”Ёзҡ„ж–№жі•жқҘзЎ®е®ҡдҪҝз”ЁBиҝӣиЎҢжҺ’еәҸж—¶йҳөеҲ—зҡ„е№іеқҮеҖјпјҹ
еҰӮжһңжҳҜ第дёҖдёӘпјҢйӮЈд№ҲжҲ‘е»әи®®дёҖдәӣз®ҖеҚ•зҡ„дәӢжғ…пјҢе°ұеғҸжҜҸдёӘйЎ№зӣ®и·қзҰ»еә”иҜҘзҡ„и·қзҰ»дёҖж ·пјҲе№іеқҮеҖјдјҡжҜ”дёҖдёӘжҖ»е’ҢжӣҙеҘҪең°еҲ йҷӨж•°з»„зҡ„й•ҝеәҰдҪңдёәдёҖдёӘй—®йўҳпјү
еҰӮжһңжҳҜ第дәҢдёӘпјҢйӮЈд№ҲжҲ‘жғіжҲ‘йңҖиҰҒдәҶи§ЈжӣҙеӨҡжңүе…іиҝҷдәӣз®—жі•зҡ„дҝЎжҒҜгҖӮ
зӯ”жЎҲ 3 :(еҫ—еҲҶпјҡ2)
и®Ўз®—RMS ErrorеҸҜиғҪжҳҜи®ёеӨҡеҸҜиғҪзҡ„ж–№жі•д№ӢдёҖгҖӮиҝҷжҳҜдёҖдёӘе°Ҹзҡ„pythonд»Јз ҒгҖӮ
def calc_error(out_A,out_B):
# in <= input
# out_A <= output of algorithm A
# out_B <= output of algorithm B
rms_error = 0
for i in range(len(out_A)):
# Take square of differences and add
rms_error += (out_A[i]-out_B[i])**2
return rms_error**0.5 # Take square root
>>> calc_error([1,2,3,4,5,6],[1,2,3,4,5,6])
0.0
>>> calc_error([1,2,3,4,5,6],[1,2,4,3,5,6]) # 4,3 swapped
1.414
>>> calc_error([1,2,3,4,5,6],[1,2,4,6,3,5]) # 3,4,5,6 randomized
2.44
жіЁж„Ҹпјҡ В еҸ–е№іж–№ж №дёҚжҳҜеҝ…иҰҒзҡ„пјҢдҪҶеҸ–жӯЈж–№еҪўеҸӘжҳҜе·®ејӮеҸҜиғҪжҖ»е’Ңдёәйӣ¶гҖӮжҲ‘и®Өдёәcalc_errorеҮҪж•°з»ҷеҮәдәҶй”ҷиҜҜж”ҫзҪ®зҡ„еҜ№зҡ„иҝ‘дјјж•°йҮҸпјҢдҪҶжҲ‘жІЎжңүд»»дҪ•зј–зЁӢе·Ҙе…·пјҢжүҖд»Ҙ:(гҖӮ
жҹҘзңӢ this question.
зӯ”жЎҲ 4 :(еҫ—еҲҶпјҡ2)
еҫҲйҡҫз»ҷеҮәдёҖдёӘеҘҪзҡ„йҖҡз”Ёзӯ”жЎҲпјҢеӣ дёәйҖӮеҗҲжӮЁзҡ„и§ЈеҶіж–№жЎҲе°ҶеҸ–еҶідәҺжӮЁзҡ„еә”з”ЁзЁӢеәҸгҖӮ
жҲ‘жңҖе–ңж¬ўзҡ„йҖүйЎ№д№ӢдёҖе°ұжҳҜжңүеәҸе…ғзҙ еҜ№зҡ„ж•°йҮҸйҷӨд»ҘеҜ№зҡ„жҖ»ж•°гҖӮиҝҷжҳҜдёҖдёӘеҫҲеҘҪпјҢз®ҖеҚ•пјҢжҳ“дәҺи®Ўз®—зҡ„жҢҮж ҮпјҢеҸӘиғҪе‘ҠиҜүжӮЁжңүеӨҡе°‘й”ҷиҜҜгҖӮдҪҶе®ғжІЎжңүиҜ•еӣҫйҮҸеҢ–иҝҷдәӣй”ҷиҜҜзҡ„дёҘйҮҚзЁӢеәҰгҖӮ
double sortQuality = 1;
if (array.length > 1) {
int inOrderPairCount = 0;
for (int i = 1; i < array.length; i++) {
if (array[i] >= array[i - 1]) ++inOrderPairCount;
}
sortQuality = (double) inOrderPairCount / (array.length - 1);
}
зӯ”жЎҲ 5 :(еҫ—еҲҶпјҡ1)
жӮЁеҸҜд»Ҙе°қиҜ•ж¶үеҸҠhamming distance
зҡ„еҶ…е®№- жҺ’еәҸеҲ—иЎЁе·®ејӮ
- з»‘е®ҡж—¶жҺ’еәҸеҲ—иЎЁжңӘжҺ’еәҸ
- дёӨеҲ—д№Ӣй—ҙзҡ„е·®ејӮжҺ’еәҸ
- sortedе’ҢsortByд№Ӣй—ҙзҡ„еҢәеҲ«
- жҹҘжүҫеңЁжҺ’еәҸеҲ—иЎЁдёӯе…·жңүзү№е®ҡе·®ејӮзҡ„ж•°еӯ—
- `sortedпјҲlistпјү`vs`list.sortпјҲпјү`жңүд»Җд№ҲеҢәеҲ«пјҹ
- жҺ’еәҸеҲ—иЎЁpython
- 2дёӘжҺ’еәҸеҲ—иЎЁд№Ӣй—ҙзҡ„е·®ејӮ
- PythonпјҡеҜ№з§°е·®ејӮжҺ’еәҸеҲ—иЎЁ
- дёӨдёӘжҺ’еәҸж•°з»„д№Ӣй—ҙзҡ„е·®ејӮ
- жҲ‘еҶҷдәҶиҝҷж®өд»Јз ҒпјҢдҪҶжҲ‘ж— жі•зҗҶи§ЈжҲ‘зҡ„й”ҷиҜҜ
- жҲ‘ж— жі•д»ҺдёҖдёӘд»Јз Ғе®һдҫӢзҡ„еҲ—иЎЁдёӯеҲ йҷӨ None еҖјпјҢдҪҶжҲ‘еҸҜд»ҘеңЁеҸҰдёҖдёӘе®һдҫӢдёӯгҖӮдёәд»Җд№Ҳе®ғйҖӮз”ЁдәҺдёҖдёӘз»ҶеҲҶеёӮеңәиҖҢдёҚйҖӮз”ЁдәҺеҸҰдёҖдёӘз»ҶеҲҶеёӮеңәпјҹ
- жҳҜеҗҰжңүеҸҜиғҪдҪҝ loadstring дёҚеҸҜиғҪзӯүдәҺжү“еҚ°пјҹеҚўйҳҝ
- javaдёӯзҡ„random.expovariate()
- Appscript йҖҡиҝҮдјҡи®®еңЁ Google ж—ҘеҺҶдёӯеҸ‘йҖҒз”өеӯҗйӮ®д»¶е’ҢеҲӣе»әжҙ»еҠЁ
- дёәд»Җд№ҲжҲ‘зҡ„ Onclick з®ӯеӨҙеҠҹиғҪеңЁ React дёӯдёҚиө·дҪңз”Ёпјҹ
- еңЁжӯӨд»Јз ҒдёӯжҳҜеҗҰжңүдҪҝз”ЁвҖңthisвҖқзҡ„жӣҝд»Јж–№жі•пјҹ
- еңЁ SQL Server е’Ң PostgreSQL дёҠжҹҘиҜўпјҢжҲ‘еҰӮдҪ•д»Һ第дёҖдёӘиЎЁиҺ·еҫ—第дәҢдёӘиЎЁзҡ„еҸҜи§ҶеҢ–
- жҜҸеҚғдёӘж•°еӯ—еҫ—еҲ°
- жӣҙж–°дәҶеҹҺеёӮиҫ№з•Ң KML ж–Ү件зҡ„жқҘжәҗпјҹ