编辑距离算法
我有一个'n'单词的字典,并且有'm'查询要响应。我想在字典中输出编辑距离为1或2的单词数。我想优化结果集,因为n和m大约是3000.
编辑从以下答案中添加:
我会试着用不同的方式说出来。
最初有'n'个单词作为一组字典单词给出。接下来给出了'm'个单词,这些单词是查询单词,对于每个查询单词,我需要查找单词是否已经存在于Dictionary(编辑距离'0')中,或者字典中单词的总计数是否在编辑距离1或者2来自字典词。
我希望问题现在是明确的。
好吧,如果时间复杂度是(m * n)n,它会超时.DP编辑距离算法的天真使用超时。甚至计算2k + 1次的对角元素,其中k是阈值,在这里k = 3。
3 个答案:
答案 0 :(得分:6)
你想在两个单词之间使用Levenshtein distance,但我想你知道,因为这就是问题标签所说的内容。
您必须遍历List(假设)并将列表中的每个单词与您正在执行的当前查询进行比较。你可以建立一个BK-tree来限制你的搜索空间,但如果你只有大约3000个单词,这听起来有点过分。
var upperLimit = 2;
var allWords = GetAllWords();
var matchingWords = allWords
.Where(word => Levenshtein(query, word) <= upperLimit)
.ToList();
编辑原始问题后添加
如果您有一个不区分大小写的字典,那么查找距离= 0的情况将很容易包含查询。距离<= 2的情况需要搜索空间的完整扫描,每个查询字的3000次比较。假设相同数量的查询词将导致900万次比较。
你提到它超时了,所以我假设你配置了超时?你的速度可能是由于Levenshtein计算的执行不力或缓慢造成的吗?

(来源:itu.edu.tr)
上图是从CLiki: bk-tree
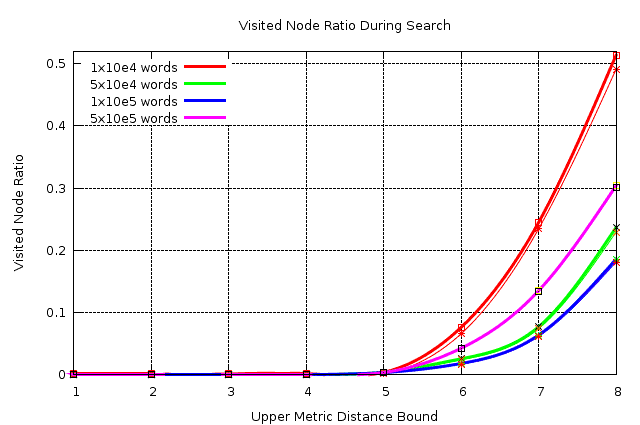{kind=link}
如图所示,使用编辑距离<= 2的bk-tree只能访问大约1%的搜索空间,但这假设你有一个非常大的输入数据,在他们的情况下高达五十万字。在你的情况下,我会假设相似的数字,但即使存储在列表/字典中,如此少量的输入也不会造成太大麻烦。
答案 1 :(得分:1)
我会试着用不同的方式说出来。
最初有'n'个单词作为一组字典单词给出。 接下来给出了'm'个单词,这些单词是查询单词,对于每个查询单词,我需要查找单词是否已经存在于Dictionary(编辑距离'0')中,或者字典中单词的总计数是否在编辑距离1或者2来自字典词。
我希望问题现在是明确的。
好吧,如果时间复杂度是(m * n)* n就超时.DP编辑距离算法的天真使用超时。 甚至计算2 * k + 1次的对角元素,其中k是阈值,在上面的情况下k = 3。
PS:BK树应该足够了。有关C ++实现的链接。
答案 2 :(得分:1)
public class Solution {
public int minDistance(String word1, String word2) {
int[][] table = new int[word1.length()+1][word2.length()+1];
for(int i = 0; i < table.length; ++i) {
for(int j = 0; j < table[i].length; ++j) {
if(i == 0)
table[i][j] = j;
else if(j == 0)
table[i][j] = i;
else {
if(word1.charAt(i-1) == word2.charAt(j-1))
table[i][j] = table[i-1][j-1];
else
table[i][j] = 1 + Math.min(Math.min(table[i-1][j-1],
table[i-1][j]), table[i][j-1]);
}
}
}
return table[word1.length()][word2.length()];
}
}
- 我写了这段代码,但我无法理解我的错误
- 我无法从一个代码实例的列表中删除 None 值,但我可以在另一个实例中。为什么它适用于一个细分市场而不适用于另一个细分市场?
- 是否有可能使 loadstring 不可能等于打印?卢阿
- java中的random.expovariate()
- Appscript 通过会议在 Google 日历中发送电子邮件和创建活动
- 为什么我的 Onclick 箭头功能在 React 中不起作用?
- 在此代码中是否有使用“this”的替代方法?
- 在 SQL Server 和 PostgreSQL 上查询,我如何从第一个表获得第二个表的可视化
- 每千个数字得到
- 更新了城市边界 KML 文件的来源?